[Text Mining] 텍스트 전처리, 자연어 전처리
이번 포스트에서는 "자연어 전처리 기초"에 대해 정리하고자 한다.
deep daiv 텍스트 마이닝 스터디 팟팅!😊😊
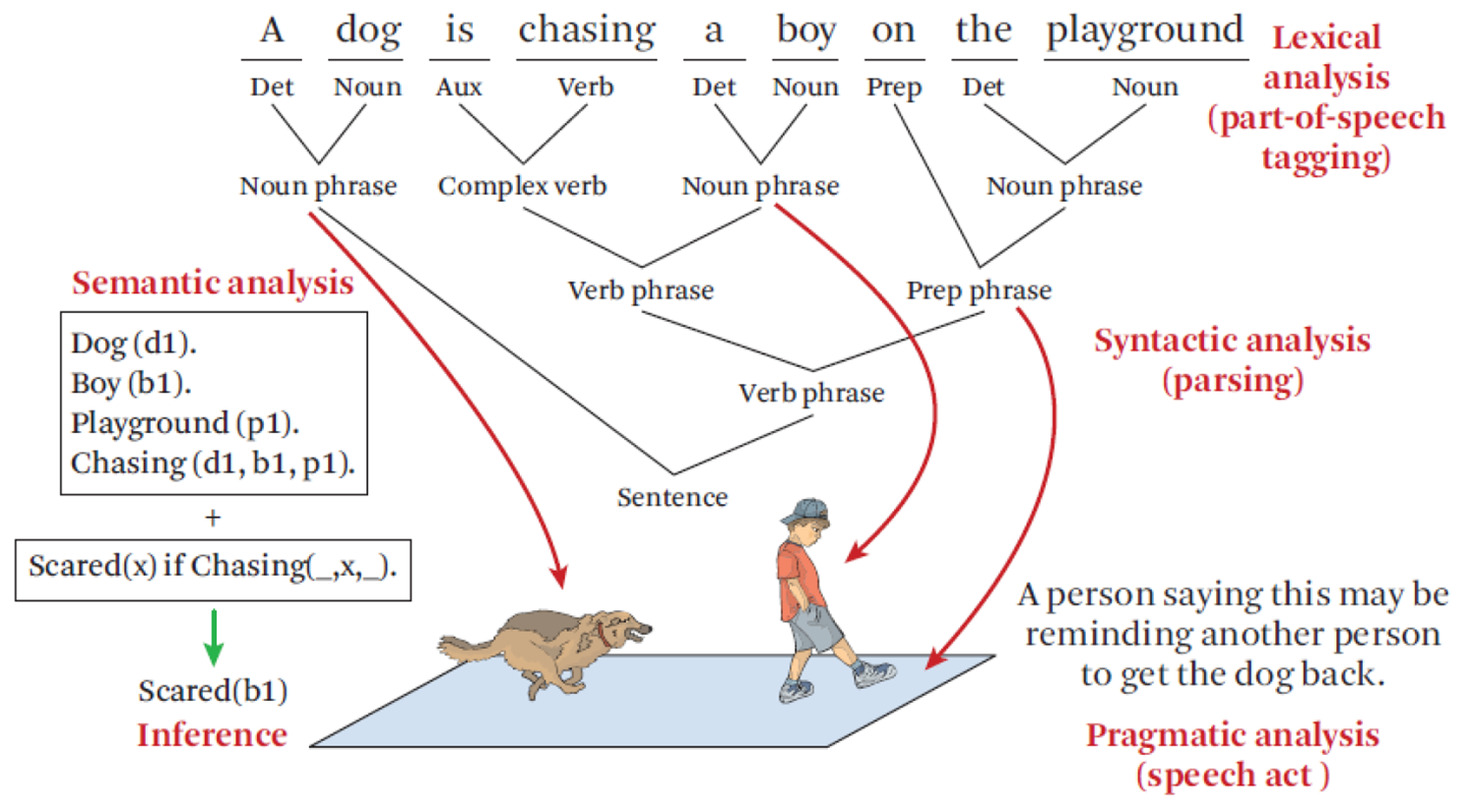
자연어 처리는 아래와 같이 크게 4가지 단계로 나눌 수 있다.
1. 정제(processing)
:특수문자뿐만 아니라 분석에 불필요한 불용어(stopwords)등을 제거하는 단계
2. 토큰화(tokenize)
단어 또는 문장을 기준으로 토큰화하는 작업(분류하는 작업?)
보통 단어를 기준으로 토큰화를 진행
3. 정규화(normalize)
같은 의미의 동일한 단어임에도 불구하고 다른 형태로 쓰였을 경우
이를, 단어의 원형으로 통일시키는 작업
4. 품사태킹(pos_tagging)
단어와 품사를 매치시키는 작업
Sentence Tokenize
: 문장을 기준으로 토큰화 하는 작업
: 주어진 텍스트를 "문장"단위로 토큰화(주로 . , ! , ? , 공백문자(를)을 이용)
=> NLTK의 sent_tokenizer함수를 이용하여 실행
이때, 한국어는 nltk.sent_tokenize를 이용하면 분리가 잘 안된다.
=> 한글을 문장을 기준으로 토큰화하고 싶을 때는
kss(korean sentence split)의 split_sentences함수를 이용하면 된다
kss.split_sentences(korean text) : korean text를 문장을 기준으로 토큰화를 진행.

Word Tokenize
: 보통 토큰화라고 하면 단어 토큰화를 칭함
: 주어진 텍스트를 "단어"기준으로 토큰화를 진행
=> NLTK의 word_tokenizer함수를 이용
이때, 어퍼스토로피( ' )를 하나의 단어로 취급하고 싶다면
Word_tokenizer대신
WordPunctTokenizer를 이용하면 된다
Word_tokenizer를 이용하면
it's 를 it / 's 이렇게 2개의 토큰으로 분리하지만
WordPuntTokenizer를 이용하면
it / ' / s 3개의 토큰으로 분리해준다.
정규표현식을 이용한 토큰화
정규표현식은 문자열에서 특정 문자(열) 패턴을 찾고싶을 때 주로 이용한다
re.findall("[abc]",text) : text에서 a, b, c중 하나라도 일치하는 문자를 가져옴

정규 표현식에 대해 간단 요약하자면.. 아래와 같다!
"[a-zA-z]" : 영어(소문자, 대문자 둘 다 포함)
"[0-9]" : 숫자
"[\w]" : 영어(대소문자), 숫자, "_"(언더바)
=> 공백을 인식을 안 함!
"[a]+" : a가 한번이상 포함
"[a]{2,5}" : a가 2번이상 5번 이하 반복
"[a]{2, }" : a가 2번이상 반복
NLTK에서의 정규표현식
nltk에서는 정규표현식 tokenizer라이브러리를 제공한다.
바로 RegExpTokenizer이다.
RegTokenizer함수에 인자로 정규표현식을 넘겨주면
그에 따른 토큰화를 진행해준다.

노이즈 및 불용어 제거
: 분석에 불필요한 단어들(빈도수가 너무 높거나, 너무 낮은 단어들) 또는
특수문자들을 제거하는 작업
우리가 따로 불용어를 지정해줘서 제거할 수 있지만
NLTK에서는 stopwords라는 라이브러리를 이용하여 불용어 사전을 제공
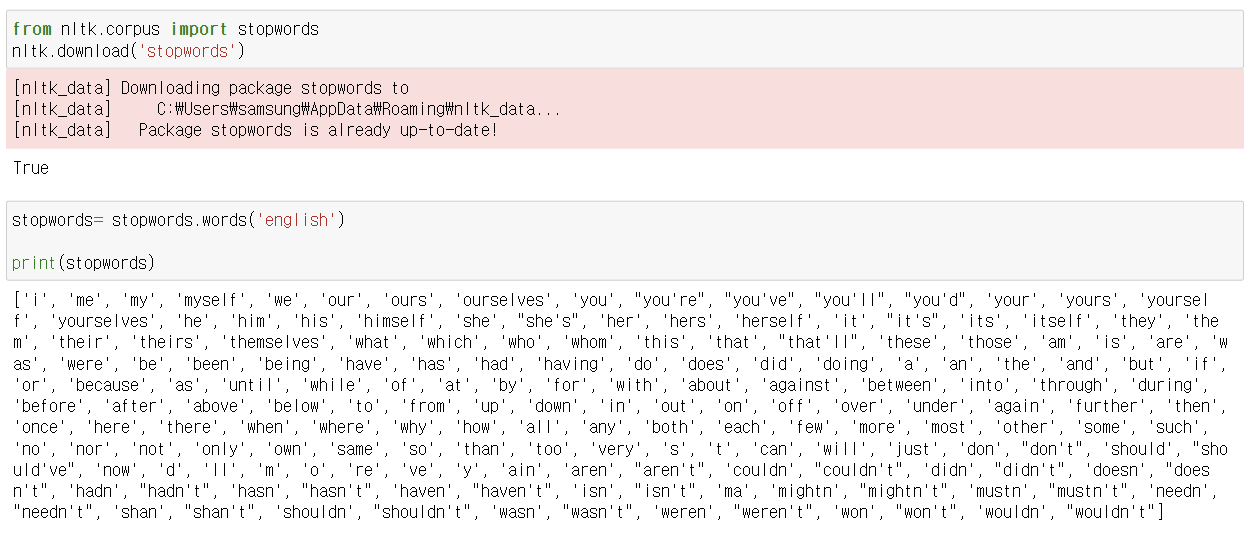
철자 교정
autocorrect에서 Speller 패키지를 통해 철차 교정을 할 수 있다.
예를 들어 'apple'이라는 단어를 모르고 'appel'이나 applee'이라고 잘못 썼을 경우
Speller('en').spell()를 이용하면 철자 교정을 한 값을 반환해준다.
객체명 인식
문장 내에 사람이름, 국가명, 장소 등과 같은 객체명이 있을 경우
nltk에서는 이를 인식할 수 있는 라이브러리인 ne_chunk를 제공한다.
*에러 발생시 nltk.download('maxent_ne_chunker')
nltk.download('words') 코드를 실행해줘야 함*
개체명 인식을 위해서는
NLTK 라이브러리의 ne_chunk 함수를 통해
텍스트 내의 개체명을 판별할 수 있다.
이를 위해서는 PoS Tagging과 Tokenization이 모두 완료되어 있는 상태여야 한다.

여기서 binary=True를 빼면 (binary는 객체명이면 NE를 아니면 공백)
NE가 아닌 구체적인 객체 유형을 반환해준다.
GPE : 위치
PERSON : 사람
ORGANIZATION: 조직, 협회

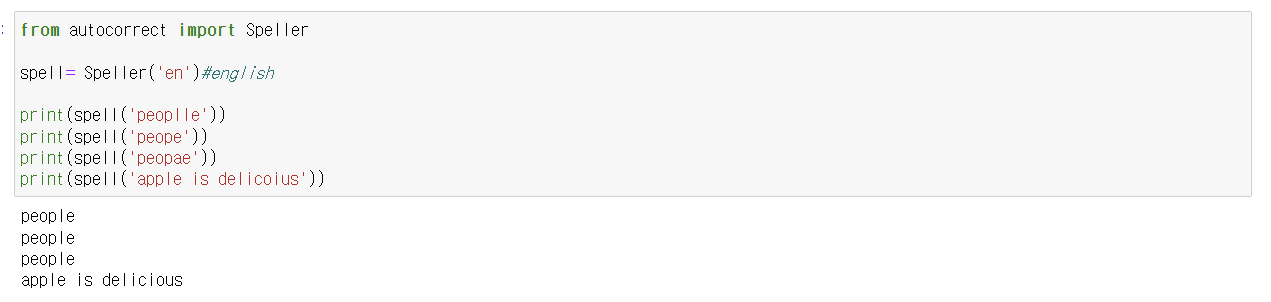
단수화 및 복수화
textblob의 sigularize, pluralize함수를 이용하면
영단어에 대한 단수화 및 복수화를 할 수 있다.
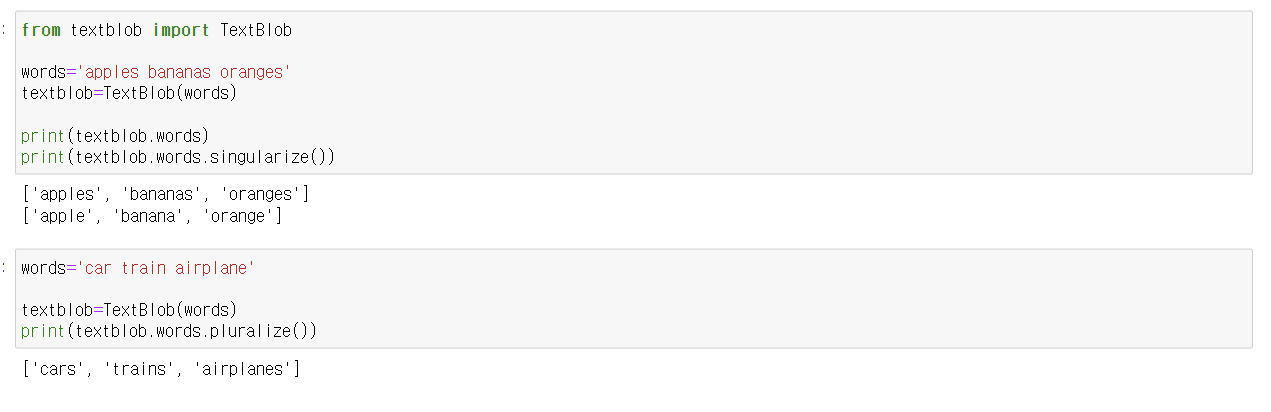
정규화
같은 의미로 쓰인 동일한 단어임에도 불구하고
다른 형태로 쓰여진 단어들을 통일해 표준 단어로 만드는 작업
즉, 다양한 변형을 원형의 형태로 통일하는 작업 = 정규화
방법에 따라 어간추출과 표제어 추출로 나뉘어짐
어간 추출(Stemming)
말 그대로 어간을 추출하는 작업
이때, 어간이란 어형변화에서 변화하지 않는 부분을 의미
예를 들어 간다, 갔다 => 여기에서는 '가'가 어형이 된다.
PorterStmmer
보통 포터 스티머를 이용하여 어간 추출을 진행
=> 모든 단어들이 같은 규칙을 기준으로 변형이 되기 때문이다.
표제어 추출(Lemmatization)
WordNetLemmatizer함수를 이용하여 표제어 추출을 진행
=> 어간 추출과 다른 점은 영어사전에 정의된 기본형으로 변환한다는 점
예를 들어 'cooking'이라는 단어를 어간추출을 한다면
'cook'으로 변환이 되는 반면
표제어 추출을 한다면 'cooking'으로 변환이 된다!
왜냐하면 cooking이라는 단어는
영어사전에 cooking(cooking자체가 단어의 원형)이라고 정의된 상태이기 때문이다.
WordNetLemmatizer는 품사를 따로 지정해주지 않으면
cooking에 대한 기본형으로 동일한 cooking을 반환
이는 사전에 요리라는 뜻으로 cooking이라는 명사가 존재하기 때문이다
그러나 품사를 나타내는 매개변수 pos에
동사를 의미하는 v를 넘겨주면(WordNetTokenizer().lemmatize('cooking', pos='v)
cook을 반환!
이는 왜냐하면, 동사인 경우에는 cooking을 기본형인 cook의 현재분사로 보기 때문이다.
이때 정확한 기본형을 알기 위해서는 품사를 알아야 하는데
품사는 문장의 문맥을 파악해야만 알 수 있다
예를 들어, 같은 cooking이더라도 "The menu is based on classic French cooking"에 나오는
cooking의 기본형은 cooking이고,
"I was cooking when he came in"에 나오는
cooking의 기본형은 cook이다.
따라서 정확한 기본형을 알기 위해서는 품사 파악이 중요--> pos_tag

위 코드에 대해 설명을 하자면
stemmer.stem('believes')는 believe의 어간인 'believ'를 출력
=> believing , belief
lemmatizer.lemmatize('believes')는 believes를 명사 belief의 복수형으로 간주하고
명사형의 원형인 belief를 반환
반면, pos를 지정해준 lemmatizer.lemmatize('believes', pos='v')는
believes를 동사 believe의 3인칭형으로 간주하고 원형인 believe를 반환
품사 태깅
단어를 토큰화를 한 뒤, 각각의 단어(토큰)에 품사를 매칭시켜주는 작업
nltk.pos_tag()를 이용
=>이때 토큰화된 단어 리스트를 넘겨줘야 한다!
결과로는 (단어, 품사)형태의 튜플 리스트를 반환해준다.
NLTK는 품사의 약어를 이용하여 품사를 나타내는데,
만약 품사의 약어를 모를 경우
nltk.help.upenn_tagset('품사약어')를 사용하면
특정 품사약어에 대한 설명을 제공한다.
이때, 한국어 문장에 대해서는 Konlpy를 이용
=> NlTK에서는 한국어를 제대로 토큰화 및 품사태깅을 못함
> Konlpy가 그 역할을 해줌
Konlpy에서는 다양한 형태소 분석기를 제공(Mecab, Kkma, Okt, Hannaum)
각각의 형태분석기는 아래와 같은 기능을 제공
t=Okt()
.morphs(text) : text를 형태소 기준으로 토큰화
.nouns(text) : text를 형태소 기준으로 토큰화한 다음에 명사만을 추출
.pos(text) : text를 토큰화하는 동시에 품사도 태깅(nltk.pos_tag와 같은 형태로 반환 (단어, 품사) )

Spacy
nltk패키지와 비슷한 역할을 함
NLTK와 다르게 Spacy는 의존 구문 분석에 용이하다.
우선, spacy.load()를 통해 특정 언어에 대한 모델을 불러와야 한다.
*최근 들어 한글도 지원한다고 함
특정 언어에 대한 모델을 불러온 다음에
모델에 text를 넘겨주면 토큰화를 진행
token.text : 토큰 텍스트 반환
token.i : 토큰 인덱스 반환
token.tag_ : 토큰 품사 태그 반환 (nltk.pos_tag()와 동일한 결과)
token.ent_type_ : 객체명 유형
=> 아래 코드에서는 Susan은 사람이름이므로 PERSON
=> Susan 외 다른 토큰들은 객체가 아니므로 빈칸
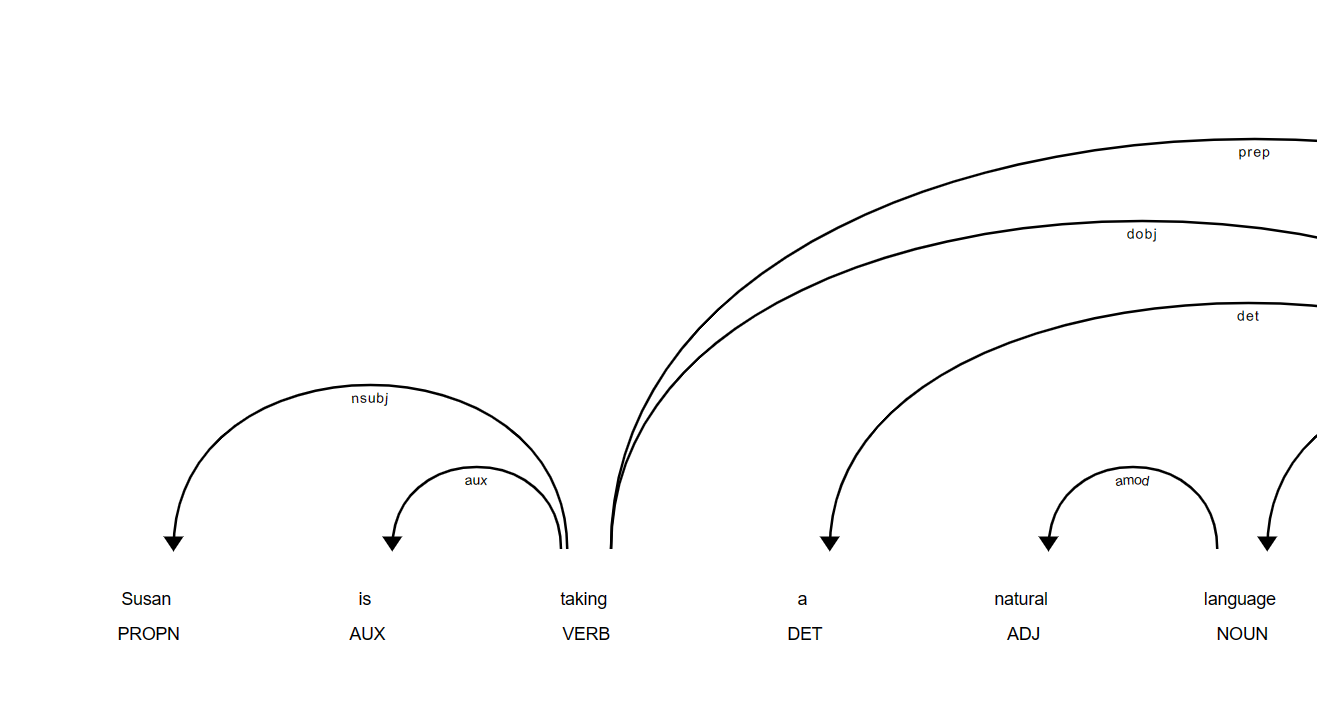
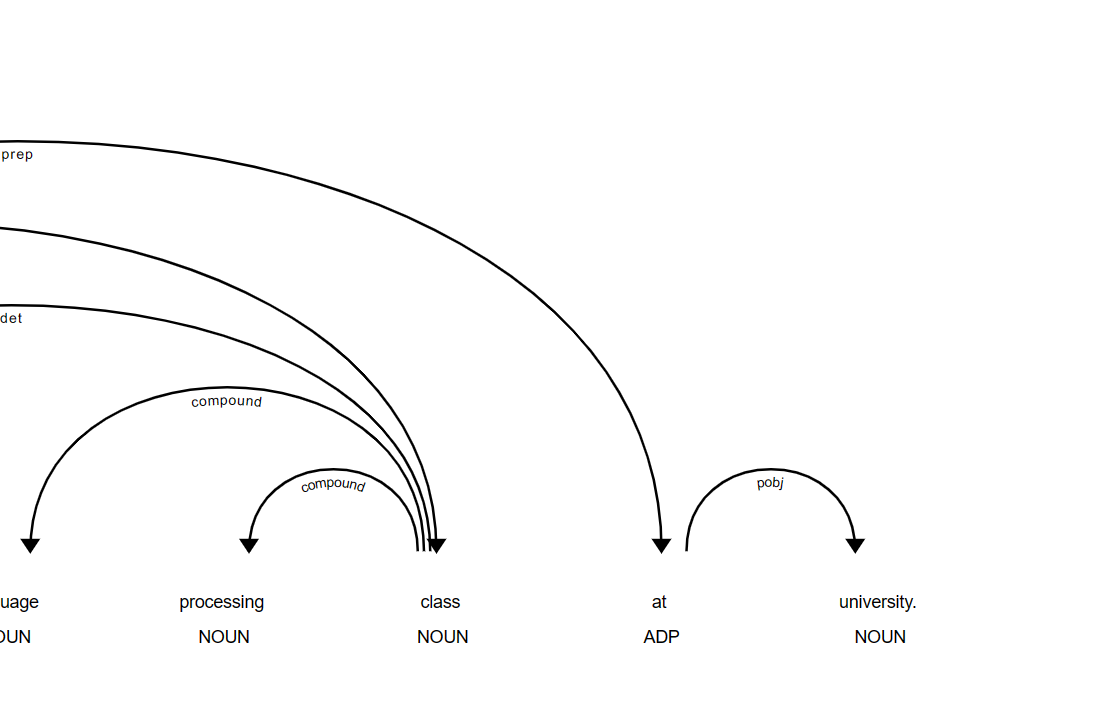
token.dep_ : parsing(문장해석, 구문해석), 즉, 위계관계 반환
token.head : 위계 관계(단어들 간의 관계 단어 반환

displacy를 통해 dep(위계관계) 시각화 가능

아래는 시각화한 결과이다.
Spacy는 displacy를 통해 문장 성분들 간의 관계를 시각화해준다.
실습코드