[DL] 정규화 (Regularization)
이번에는 "정규화"에 대해 이야기 해보고자 한다.
정규화에 대해 이야기 해보기 전에 먼저 오버피팅부터 복습해보자!
오버피팅이란
학습오차가 일반화 오차에 비해 현격하게 낮아지는 현상,
즉 모델이 학습 데이터의 불필요한 특징들까지 학습을 하여
모델의 일반화 성능이 떨어지는 상황을 말한다.
우리는 오버피팅을 방지하기 위해 여러가지 방법을 배웠는데,
한가지만 말해보자면,
검증 데이터셋과 테스트 데이터셋을 도입하여
모델의 최적화 과정에서 발생할 수 있는 오버피팅 현상을 방지 할 수 있었다.
정규화를 통해서도 오버피팅을 방지할 수 있는데,
정규화에는 데이터 증강, 배치정규화 등 여러가지 방법이 존재한다.
정규화
오버피팅을 늦추고
모델이 학습 데이터로부터 적절한 특징을 학습하여
일반화 오차를 낮춰줄 수 있는 기법을 말한다.
이때 모델이 학습데이터에 과도하게 학습되는 것을
막기 위해 학습 과정에서 약간의 노이즈를 추가해야 하므로
학습 오차가 높아질 수도 있다.

가중치 감쇠
가중치 감쇠는 정규화 방법 중 하나로,
가중피 파라미터가 학습되는 것을 방해하여 오버피팅을 방지하는 기법이다.
가중치 파라미터가 학습되는 것을 방해하는 기법이므로
기본적으로 손실 함수를 수정해야 한다.
보통은 기존의 손실함수에 가중치 파리미터의 l2 norm을 더하는 방식으로 수정이 된다.
아래 수식이 가중치 감쇠 기법을 적용한 수정된 손실함수이다.

기존의 손실함수 L(θ)에 가중치 파라미터, W의 l2 norm을 더함으로써
이 두가지 값을 동시에 최소화하도록 손실 함수가 수정되었다.
그렇다면 위와 같이 수정된 식이 어떤 원리를 이용하여 가중치 파라미터 학습을 방해하는 것일까?
우리가 보통은, 즉 l2 norm을 더하지 않은 기존의 손실함수를 적용했을 경우에는
손실함수만 최소화 시키는 방향으로 작업을 수행한다.
하지만 가중치 감쇠 기법을 적용하여
수정된 손실함수로 작업을 수행해야 하는 경우
기존의 손실함수만 최소화 시키는 것이 아니고, l2 norm 또한 최소화 시켜야 하므로
기존의 손실 함수를 최소화 시키는 것을 방지
즉, 보통의 경우보다 신경을 쓰지 못하게 되므로 당연하게 방해가 된다.
따라서 위의 식을 통해 가중치 파라미터가 학습되는 것을 방해할 수 있는 것이다.
이때 가중치 감쇠 기법은 W에 대해서만 적용할 수 있고,
b는 가중치 감쇠에서 제외되는 것을 유의해야 한다.
왜?
가중치 파라미터에서 W의 각 요소들은
선형 계층에서 입출력 노드 사이의 관계를 나타낸다.
즉, 요소 값의 크기가 클수록 강한 관계임을 의미한다고 볼 수 있다.
이때 W에 L2 norm을 취하여 관계를 약화함으로써, 노드 사이의 관계의 강도를 제한하여
각 계층의 출력 노드가 다수의 입력 노드로부터 많이 학습하는 것을 제한할 수 있다.
반면, 편향, b는 W를 곱한 값에 더해주기만 하면 되니까
큰 영향을 끼치지는 않을 것이므로
가중치 감쇠는 b에는 해당이 안되고, W에만 적용을 하는 것이다.
즉,

그렇다면 가중치 감쇠는 어떻게 구현할까?
우리는 가중치 파라미터가 학습되는 것을 방해해야 하는 것이기 때문에
Optimizer를 생성할 때 파라미터를 통해 가중치 감쇠를 간단하게 구현할 수 있다.

그림의 weight_decay 파라미터가 앞서 수식에서의 하이퍼파라미터 를 의미한다.
디폴트 값이 0이기 때문에 보통은 가중치 감쇠가 적용되지 않도록 설정되어 있다.
만약, 가중치 감쇠를 적용하고 싶다면 weigh_decay에 숫자를 넘겨주면 된다.
데이터 증강
데이터 증강은 데이터를 통해 오버피팅을 피하고 모델의 일반화 성능을 개선하는 방법이다.
이때, 데이터의 핵심 특징은 간직한 채, 노이즈를 더하여 데이터셋을 확장해야 한다.
데이터 증강은 다양한 유형의 데이터에 적용할 수 있는데 보통은 이미지 데이터에 사용한다.
이미지 데이터 증강 기법에는 여러가지가 있다.
1. 소금과 후추
가장 간단하게 이미지를 증강할 수 있는 방법으로,
소금과 같이 하얀색 점들을 임의로 흩뿌리거나, 후추와 같이 검정색 점들을 임의로 흩뿌리는 기법이다.
아래 사진을 보자.

위의 사진과 같이 일부 노이즈가 추가되더라도 여전히 사람 눈에는 같은 이미지인것처럼,
컴퓨터도 마찬가지로 같은 이미지라고 판단할 수 있어야 하기 때문에,
굉장히 간단하면서도 효과적인 노이즈 추가 기법이다.
이러한 노이즈 추가 과정에서 불필요한 특징들이 노이즈에 의해 제거되거나 변형될 수 있으며,
이로인해 모델의 일반화 성능이 높아질 수 있다.
2. 회전과 이동, 뒤집기

뒤집기의 경우에는 사람의 얼굴은 좌우 대칭이므로,
좌우 수평 뒤집기 기법은 얼굴 데이터 증강에 유용하게 활용될 수 있다.
예를 들어 MNIST와 같이 글씨를 인식하고자 할 때에는
일부 뒤집기가 가능한 경우(가령 숫자 0 또는 8)도 있겠지만
대부분은 뒤집기를 할 경우 존재하지 않는 글씨가 될 수 있다.
이와 같이 데이터를 면밀히 분석한 후,
데이터에서 성립하는 가정을 통해 데이터 증강을 수행할 수 있을 것이다.
마찬가지로 회전과 이동의 경우에도
데이터의 주요 특징들을 손상시키지 않는 범위내에서 수행할 수 있다.
당장 이러한 기법들을 적용하면 최소 수 배에서 최대 수십 배에 이르는 데이터의 확장을 기대할 수 있을 것이다.
이미지 외에도 텍스트에도 데이터 증강 기법을 적용시킬 수 있는데,
자연어 문장의 경우 생각보다 어순 변화나 단어의 변화에 민감하기 때문에 생각처럼 잘 동작하지 않을 수 있고,
또한 규칙에 의해서 문장을 변형할 경우, 규칙 자체를 신경망이 학습할 수 있기 때문에 위험할 수 있기에
텍스트 데이터에 대해서는 증강 기법을 사용하지 않는 편이다.
이처럼 데이터 증강의 경우에는 쉽게 데이터를 확장시킬 수 있고,
신경망의 구조나 학습 기법의 수정 없이 정규화를 적용할 수 있다는 장점이 있다.
하지만 데이터를 실제로 더 수집하는 것에 비해서는
훨씬 낮은 성능 개선을 얻을 수 밖에 없고, 그 한계도 굉장히 명확하다.
예를 들어서 백인 얼굴 이미지를 아무리 증강한다해도,
인종에 대한 다양성을 확보할 수 없는 것과 마찬가지이다.
(데이터를 증강한다고 해도 기존의 데이터에서 변형을 진행하는 것이기 때문에 흑인 데이터는 얻을 수 없음)
다만 다양한 백인 얼굴들 사이의 중간 빈 공간을 메꿔줄 수는 있을 것이다.
즉, 다시 말해 데이터를 증강한다는 것은 새로운 지식을 배우는 것이 아니라,
오히려 최적화를 수월하게 수행할 수 있도록 도와주는 측면이 더 강하다고 볼 수 있다.
드롭아웃
드롭아웃을 간단히 말하자면, 신경망 중간에 노이즈를 추가하는 기법이다.
어떻게?
임의의 노드를 일정 확률로 드롭해서 학습에 참여하지 않도록 하여 신경망 중간에 노이즈를 추가한다.
데이터를 신경망에 통과시키는 과정에서 노드가 생략되므로,
자연스럽게 역전파에서도 제외된다.
아래 그림을 보자!
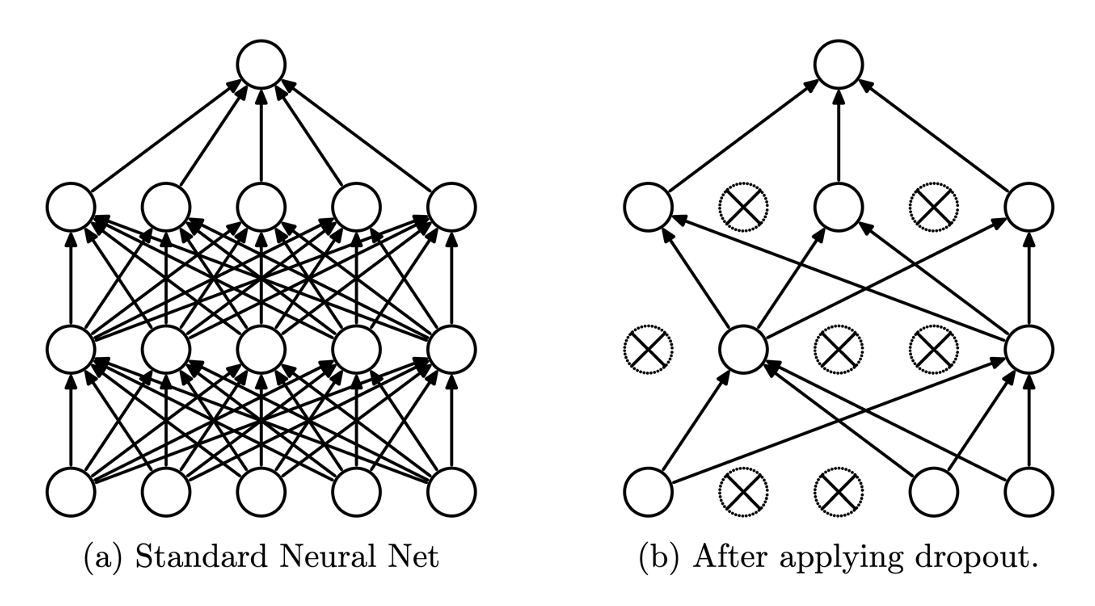
왼쪽(a)은 보통의 심층신경망이고, 오른쪽(b)은 드롭아웃을 적용한 신경망을 나타낸다.
b를 보면 중간 중간에 노드들이 x가 되어있는 것을 볼 수 있는데,
이 노드들이 바로 드롭된 노드들이다.
드롭된 노드들을 보면 해당 노드와 연결된 가중치들도 끊어지는 것을 볼 수 있다.
드랍되는 노드는 매 미니배치마다 이항분포을 활용하여 랜덤으로 선정이 된다.
이때 노드의 드랍 확률 가 하이퍼파라미터가 되어, 사용자가 최적의 설정 값을 찾아주어야 한다.
여기서 주의!
드랍아웃에서는 학습과 추론 방법에 차이가 있으므로 주의해야 한다.
위에서 설명한 드랍아웃의 동작 방법(노드들이 드롭 되는 것)은 학습에서만 적용되는 방법이다.
추론에서는 드랍되는 노드 없이 모든 노드가 항상 추론에 참여한다.
이때 추론할 때 중요한 점은 가중치 파라미터 에 를 곱해주어야 한다는 것이다.
왜?
예를 들어 앞서 그림과 같이 하나의 출력 노드가 3개인 선형 계층이 있다고 가정해보자.
그런데 만약 0.33의 확률로, 즉 p가 0.33일 때, 출력 노드에 드랍아웃이 적용되었다면,
학습할 때에는 평균적으로 2개의 노드만 살아남을 것이다.
따라서 학습시에는 다음 계층은 평균적으로 3개 중에서 2개 노드로부터 값을 전달 받을 것이다.
하지만 추론시에는 다음 계층은 항상 전체 노드로부터 값을 전달 받을 것이다.
즉, 추론시에 다음 계층은 평균적으로 학습시보다 1.5배 큰 입력 값을 전달 받는다는 말이다.
그러므로 우리는 이것을 상쇄시키기 위해 추론시에는 가중치 파라미터에 을 곱해주어야 한다.
드랍아웃은 이전까지 소개한 정규화 기법과 달리 신경망의 계층으로 구현될 수 있다고 했다.
파이토치에서는 미리 구현된 드랍아웃 계층을 제공하는데,
우리는 이것을 활용하여 쉽게 드랍아웃을 구현할 수 있다.
>> nn.Dropout(p) : 인수로 확률값 넘겨주면 된다.

보통 드랍아웃이 구현되는 위치는 위의 그림과 같이 활성 함수와 다음 계층 사이가 된다.
참고로 보통은 신경망의 양 끝단인 입력 계층 이전과 출력 계층 이후에는 드랍아웃이 적용되지 않는다.
드랍아웃은 신경망의 중간에 노이즈를 추가하는 기법이라고 했다.
다시 생각해보면, 드랍아웃은 임의의 노드를 학습에서 생략하는 과정을 통해
특정 노드 사이의 관계가 불필요하게 강해지는 것을 방지하며,
앞서 다른 정규화 방식과 마찬가지로 학습을 방해하는 방식으로 동작한다는 것을 알 수 있다.
따라서 드랍아웃이 적용되면 비록 일반화 성능이 개선될 수는 있어도
손실 값의 수속도가 저하될 수 있고 학습 오차가 증가될 수 있다.
또한 노드의 드랍 확률 값 하이퍼파라미터가 추가됨으로써, 사용자의 추가적인 튜닝을 요구하게 된다.
배치정규화를 사용하면 위와 같은 문제를 해결할 수 있다.
배치정규화
배치정규화 기법은 드랍아웃과 마찬가지로 신경망 계층으로 구현되어 작동할 수 있는 정규화 기법이다.
또한 이 뿐만 아니라, 드랍아웃처럼 모델의 모드 전환에 따라 다르게 동작한다는 점도 같다.
드랍아웃을 비롯하여 기존의 정규화 기법들은 대부분 학습을 방해하는 형태로 작용한다.
따라서 대부분 일반화 성능을 개선하기 위해 학습 및 수렴 속도가 느려지게 되는 단점도 존재하게 된다.
하지만 배치정규화 기법의 경우, 학습 속도를 비약적으로 향상시킬 수 있을 뿐만 아니라,
일반화 성능까지 대폭 개선할 수 있는 훌륭한 방법이다.
학습과 추론에서의 동작 방식이 다르다고 했는데, 어떻게 다를까?
배치정규화가 추론에서 동작이 다른 이유는 바로 미니배치의 평균과 표준편차를 구하는 방식 때문이다.
배치정규화 수식을 살펴보자.

수식을 살펴보면, 미니배치를 단위 가우시안 분포로 바꾸는 정규표준분포화한 이후에
스케일 파라미터 와 이동 파라미터 를 적용한다.
즉, 매 신경망을 통과하는 미니배치마다 해당 미니배치의 평균과 표준편차를 구하고,
이를 활용하여 표준정규분포화를 수행한다는 말이다.
예를 들어, 미니배치가 256개의 샘플들로 이루어져 있다고 했을 때,
우리는 전체 256개의 샘플들을 살펴보고 이들의 통계 수치를 계산하는 것이라고 볼 수 있다.
하지만 미니배치 내에서 번째 샘플에 대한 추론을 수행할 때,
번 이후의 샘플들을 살펴보는 것은 반칙과 다름이 없다.
즉, 추론 과정에서 미니배치의 전체 샘플들을 살펴보고 통계를 구하는 것은 올바르지 못한 방법이다.
따라서 추론 과정에서는 들어오는 샘플들에 대한 이동평균과 이에 따른 표준편차를 계산하고,
이를 활용하여 각 샘플들에 대략적인 표준정규분포화를 수행해야 한다.
이처럼 배치정규화도 드롭아웃처럼 학습과 추론할 때 방식에 차이가 존재한다.
삽입 위치는?
배치정규화 삽입위치 또한 드롭아웃과 동일하게 신경망 내부에 계층으로 구현할 수 있다.
>>nn.BatchNorm(batch_size) : 인수로 이전 계층의 output_size를 받아야 함
활성화 함수와 다음계층 사이에 넣어주면 된다.

이처럼 배치정규화는 기존의 정규화 기법들과 달리,
튜닝이 필요한 하이퍼파라미터가 추가되지 않는다는 점이 가장 큰 특징이자 장점이다.
이 뿐만 아니라 배치정규화를 적용할 경우, 정규화로 인한 일반화 성능 개선 뿐만 아니라,
학습과 수렴 속도가 빨라지는 장점도 존재한다. ( 드롭아웃의 한계점 해결 )
코드 실습
이전의 글 보면 대부분 신경망을 구현할 때
nn.Sequential에 원하는 계층과 활성함수를 집어넣어 쉽고 간편하게 모델을 구현할 수 있었다.
우리가 신경망을 구현할 때를 생각해보면 신경망은 선형 계층과 비선형 활성 함수의 반복이었다.
즉, 하나의 층이 선형 계층과 비선형 활성 함수의 조합으로 이루어지게 되고,
이것을 전체 모듈에 대한 부분 모듈 또는 서브 모듈로 볼 수 있다.
그렇다면 우리는 전체 모듈에 대해서
서브 모듈이 입출력 크기만 바뀌어서 반복되고 있던 것으로 볼 수 있다.
이번에는 여기에 정규화 계층이 더해져 “선형 계층 + 비선형 활성 함수 + 정규화 계층”이 하나의 서브 모듈이 될 것이고,
마찬가지로 입출력 크기만 바뀌어서 반복 사용이 될 것이다.
그럼 이것에 착안하여 서브 모듈을 nn.Module을 상속받아 하나의 클래스로 정의하고,
nn.Sequential에 “선형 계층 + 비선형 활성 함수 + 정규화 계층”을 각각 인자로 넣어주는 대신에,
정의한 클래스 객체를 넣어주면 될 것이다.
아래 코드는 서브 모듈 클래스를 정의하는 코드이다.
#선형 + 활성화 + 정규화 계층이 하나의 서브 모듈
#서브 모델이 입출력 크기만 바뀌어서 반복 사용
#서브모듈 구현
class Block(nn.Module):
def __init__(self, input_size, output_size, use_batch_norm, dropout_p=.4): #필요한 기능 선언
self.input_size=input_size
self.output_size=output_size
self.use_batch_norm=use_batch_norm #use_batch_norm에는 boolean값을 넘겨주면 된다. 사용할거면 True
self.dropout_p=dropout_p
super().__init__()
def get_regularizer(use_batch_norm, size): #정규화 계층
return nn.BatchNorm1d(size) if use_batch_norm else nn.Dropout1d(dropout_p)
#서브 모듈 : 선형 계층 + 활성화 함수 + 정규화 계층
self.block=nn.Sequential(
nn.Linear(input_size,output_size),nn.LeakyReLU(),
get_regularizer(use_batch_norm,output_size),)
def forward(self, x): #기능 구현
y=self.block(x)
return y이 모듈은 생성시에 배치 정규화와 드랍아웃중에서 선택받고, 입출력 크기를 입력받는다.
그래서 self.block에 선형 계층, 리키 렐루, 정규화 계층을 nn.Sequential에 넣어 가지고 있다.
배치 정규화를 사용한 경우에는, 즉 use_batch_norm이 True인 경우,
바로 이전에 사용된 선형 계층의 출력 크기를 넣어주어야 하고,
드랍아웃의 경우에는 확률 값을 넣어주어야 한다.
그리고 forward 함수에서 피드포워드(심층신경망 통과)를 구현해준다.
이렇게 정의된 Block 클래스를 곧이어 정의할 MyModel 클래스에서 활용할 계획이다.
다음의 코드는 MyModel 클래스를 정의한 코드로, nn.Module을 상속받아 만들었다.
#전체 계층 구현
class Mymodel(nn.Module):
def __init__(self, input_size, output_size, use_batch_norm, dropout_p=.4): #필요한 기능 선언
super().__init__()
self.layers=nn.Sequential(
Block(input_size, 500, use_batch_norm,dropout_p),
Block(500, 400, use_batch_norm,dropout_p),
Block(400, 300, use_batch_norm,dropout_p),
Block(300, 200, use_batch_norm,dropout_p),
Block(200, 100, use_batch_norm,dropout_p),
Block(100, 50, use_batch_norm,dropout_p),
nn.Linear(50,output_size),
nn.LogSoftmax(dim=-1))#다중클래스 분류문제이므로 마지막에 로그소프트 맥스 활성화 함수 이용
def forward(self,x):
y=self.layers(x)
return y마찬가지로 init 함수에서 필요한 객체들을 미리 선언해주는데,
self.layer는 nn.Sequential 객체를 가지고 있고, 그 내부는 Block 클래스 객체들로 채워져 있다.
아래는 최종 모델을 선언한 결과이다.

그리고 나머지는 이전 글의 실습과 동일하게 진행해주면 된다.
2023.05.22 - [STUDY/DeepLearning] - [DL] 심층신경망을 활용한 다중분류 (MNIST 실습)
[DL] 심층신경망을 활용한 다중분류 (MNIST 실습)
바로 앞에서 심층신경망을 활용하여 이진 분류를 수행하는 방법에 대해 글을 올렸다. 이진분류를 위해서 우리는 심층신경망의 가장 마지막 계층 이후에 시그모이드 활성 함수를 넣어주어 확률
pej2834.tistory.com
모델만 다르게 구현하고 (정규화 과정 추가),
epoch수, optimizer종류 등 나머지 설정은 바꾸지 않고 진행한 결과,
test_accuracy는 약 98%로 지난 실습대비 1%가 상승했다.
또한, 혼동 행렬을 보면
이전 글의 실습에 비해 대각 성분의 값이 더 커지고 나머지 값들은 줄어든 것을 확인할 수 있다.

이처럼 우리는 정규화를 도입하여 모델의 오버피팅을 최대한 지연시키고
일반화 성능을 향상시킬 수 있음을 확인할 수 있다.