
사용자 일기에 대한 다중 감정 분류를 진행하기 위해
KoBERT 파인튜닝 과정을 기록하겠습니다!✍️✍️
KoBERT모델을 아래 공식 링크를 참고하여 불러오면 됩니다.
https://github.com/SKTBrain/KoBERT
GitHub - SKTBrain/KoBERT: Korean BERT pre-trained cased (KoBERT)
Korean BERT pre-trained cased (KoBERT). Contribute to SKTBrain/KoBERT development by creating an account on GitHub.
github.com
데이터셋은
AI Hub에서 제공한 감성 대화 말뭉치 데이터를 사용했습니다!
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=86
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
aihub.or.kr
이제부터..
KoBERT 튜닝을 향한 저의 삽질이 담긴 과정을 적어보도록 하겠습니다,,,🥹🥹
그냥 공식 링크에 나와있는 코드에서 파라미터만 약간 수정하고
실행시킨 결과

train acc는 높은데 , test acc가 낮은 것을 확인할 수 있었는데요.
이를 "과적합"이라고 생각하고
과적합 해결을 위해
dropout비율을 0.3에서 0.5로 증가
및
정규화를 위해 laynorm 레이어를 모델에 커스텀을 진행하였습니다.
여기서, 정규화하면 보통 배치 정규화를 생각할 텐데,
저는 LayerNorm Regularization을 사용했습니다.
그 이유는 아래 2가지때문인데요!
순환 신경망(RNN) 구조에 적합:
KoBERT를 사용하여 한국어 텍스트의 감정 분류를 수행할 때,
대부분의 경우에는 순환 신경망보다는 Transformer와 같은 어텐션 메커니즘을 사용.
Layer Normalization은 이러한 Transformer 구조에 더 적합하게 설계되어있음
미니배치 크기에 덜 민감:
LayerNorm은 미니배치 크기에 상대적으로 덜 민감하며,
KoBERT와 같이 사전 훈련된 언어 모델을 사용할 때 미니배치의 크기에 따른 영향을 줄일 수 있음
이러한 2가지 이유로 배치 정규화보다는 LayerNorm Regularization을 사용하였고,
이를 반영하여 모델 구조는 아래와 같이 커스텀을 했습니다.
#입력 데이터의 패딩 부분을 제외하고, 실제 입력에 대한 어텐션 마스크를 생성하는 함수
class BERTClassifier(nn.Module):
def __init__(self,
bert,
hidden_size = 768,
num_classes=6,
dr_rate=None,
params=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=hidden_size, out_features=512),
nn.Linear(in_features=512, out_features=num_classes)
) #nn.Linear(hidden_size , num_classes)
#정규화 레이어 추가 (Layernormalization)
self.layer_norm = nn.LayerNorm(768)
#드롭아웃
self.dropout = nn.Dropout(p=dr_rate)
def gen_attention_mask(self, token_ids, valid_length): #token_ids는 입력 문장을 토큰화한 결과
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length) #gen_attention_mask 메서드를 사용하여 어텐션 마스크를 생성
_, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device)) #BERT 모델에 입력을 전달하여 출력을 계산
pooled_output = self.dropout(pooler)
normalized_output = self.layer_norm(pooled_output) # Layer Normalization 적용
out=self.classifier(normalized_output)
return out
하지만..
모델 구조를 커스텀했음에도 불구하고,
test acc가 처음보다는 좋아졌지만 여전히 낮은 수치를 보였는데요..
여기서 저는 데이터셋의 문제라 판단을 하고,
데이터 전처리를 하기로 결심했습니다🥹🥹
기존의 데이터 라벨은 "기쁨", "슬픔", "분노", "불안", "상처", "당황" 이렇게 총 6가지가 있었는데,
저는 여기서 슬픔이랑 상처는 비슷한 유형의 감정이라고 판단을 하고
두개의 레이블을 하나로 합쳤습니다.
## 상처와 슬픔을 하나의 레이블로 설정
#분노, 불안, 상처, 기쁨, 슬픔, 당황
train_set.loc[(train_set['label'] == '불안'), 'label'] = 0
train_set.loc[(train_set['label'] == '분노'), 'label'] = 1
train_set.loc[(train_set['label'] == '상처'), 'label'] = 2
train_set.loc[(train_set['label'] == '슬픔'), 'label'] = 2
train_set.loc[(train_set['label'] == '당황'), 'label'] = 3
train_set.loc[(train_set['label'] == '기쁨'), 'label'] = 4
train_set['label']=train_set['label'].astype(int)
validation_set.loc[(validation_set['label'] == '불안'), 'label'] = 0
validation_set.loc[(validation_set['label'] == '분노'), 'label'] = 1
validation_set.loc[(validation_set['label'] == '상처'), 'label'] = 2
validation_set.loc[(validation_set['label'] == '슬픔'), 'label'] = 2
validation_set.loc[(validation_set['label'] == '당황'), 'label'] = 3
validation_set.loc[(validation_set['label'] == '기쁨'), 'label'] = 4
validation_set['label']=validation_set['label'].astype(int)
이렇게 전처리를 하고 코드를 실행한 결과 더 개선이 되었음을 확인할 수 있었습니다!
하지만 아직도 test 0.65정도의 낮은 수치를 보였는데요,,
그래도 아까보다는 0.1정도 개선이 된 걸 보니 뭔가 희망이 보이기 시작하네요..🥹🥹

여기서 저는 무엇을 더 해야하는지 엄청 고민을 했었습니다..
모델은 완벽한 거 같은데, 도대체 무엇이 문제일까...
:
그래서 내린 결론이
"평가지표를 잘못된 걸로 판단하고 있나?" 였습니다
생각해보니까..
보통 분류 문제에서는 ACC보다는 F1-score로 평가지표를 사용한다는 사실을 까먹고 있었어요..
(오래 전에 공부하면서 알았던 사실인데....왜 이걸 이제야 기억했을까요...?🥹🥹)
F1 score는 precision과 recall이 모두 높으면 높고 0.0 ~ 1.0 사이의 값을 가지는데 (e.g. 0.87, %아님 주의),
한 슈퍼마켓에서 buyer와 looker를 분류하는 예시로 설명하자면
99명이 looker(negative)이고 1명이 buyer(positive)인 경우
모두 looker로 분류한 모델을 Accuracy(정확도)로 평가하면
99%의 정확도라는 썩 괜찮은 모델같지만,
F1 score로 평가하게 되면 0이 나오게 됩니다.
이러한 이유로
데이터 불균형이 심한 다중 클래스 분류 문제에서는
보통 평가지표로 F1-score를 사용합니다!!
:
위에서 설명했듯이 클래스 두개를 하나로 합쳐서
데이터 자체에 클래스의 불균형이 발생하게 되었으니까
평가지표를 ACC에서 F1-score로 바꾸겠습니다!
:
이때 주의해야 점!!
f1-score는 average라는 파라미터가 있는데,
default값 그대로 사용한다면 에러가 발생하게 됩니다!
다중 클래스에서 f1_score를 사용하기 위해서는 average값을 변경해야 하는데요!
average에는 다양한 값이 존재하는데
저는 다중 클래스 불균형에 좀 더 적합한 "macro"로 설정하였습니다!
각 값마다 장점이 있으니 공식링크 참고하면 좋을 거 같아요!☺️☺️
공식 링크 : https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html
평가지표를 재설정하고 다시 코드를 돌린 결과
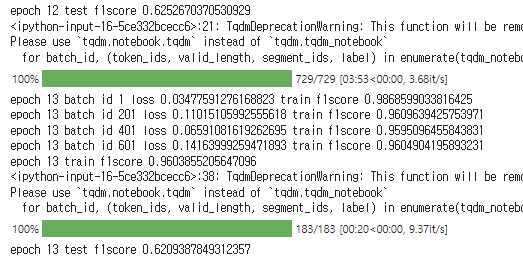
0.6정도로 바로 위에서 나온 Accuracy결과와 비슷한 수치인데요!
위에서 설명했듯이
accuracy 0.6과 f1 score가 0.6인 것은 해석이 다릅니다!
f1 score에서 0.6은 60%를 의미하는 것이 아니에요!
하지만 그렇다고 해도, 좋은 수치는 아니듯해보입니다...
그냥 데이터 수집을 하여서 데이터의 imbalance를 해결해야겠습니다..
:
우선, 해당 모델로 임의의 문장을 넣어서 Test를 진행해봤는데요

결과는 잘 나오네요?!
그래도 평가지표 개선을 위해..
2탄으로 돌아오겠습니다! 🖥️🖥️
'💭 Ideation > NLP' 카테고리의 다른 글
| KoBERT로 다중 감정 분류 성능 개선을 위한 FineTuning 도전, 2탄 (0) | 2023.12.29 |
|---|