
CLIP 논문을 읽고 핵심 내용만 정리함.
논문 링크: https://arxiv.org/abs/2103.00020
모델 등장 배경
Vision Model은 전통적으로 이미지를 입력받아 어떻게 모델을 구성하면 더 좋은 표현을 학습하는지를 고민해왔으며, 그덕분에 날이 갈수록 발전함.
하지만 이미지만 학습한 모델은 고질적으로 일반화 능력이 부족하고 작은 노이즈에도 취약한 약점을 보임.
한편 Language Model은 Vision Model 보다 한 발 앞서 나아가는 형태로 발전
이에, “Vision Model도 LLM과 같은 방향으로 간다면 한 단계 더 발전할 수 있지 않을까?”라는 고민을 하게 되고,
“데이터셋이라도 아주 크게 만들어서 학습한다면 지금의 Vision Model의 한계를 넘어설 수 있지 않을까?”라는 결론에 도달
당시 Vision Model의 대표 데이터셋은 ImageNet 이었으며, 데이터의 양이 적은편은 아니지만, 각 이미지에 대해 사람이 직접 Label을 달아놓은 형태의 데이터셋을 이용. 그 말은 아무래도 데이터의 개수에 한계가 있다는 것을 의미함. (왜냐하면, 사람이 직접 Label을 달아서는 수집할 수 있는 개수에 한계가 있으므로)
ImageNet으로 대표되는 Labeled Image Dataset으로 학습하는 Vision Model의 한계에 대해 고민하게 되고, 이러한 상황을 극복, 해결해준 것이 CLIP이다.
모델의 KeyPoint
CLIP모델은 NL를 supervision으로 학습한다. 기존의 많은 이미지 데이터셋들과는 다르게, Labeling이 필요없다는 엄청난 장점을 갖고 있음.
Contrastive Learning
이전의 연구들은 대부분 다음과 같은 세 가지 데이터셋을 많이 사용:
- MS-COCO (높은 퀄리티, 적은 양)
- YFCC100M (높은 퀄리티, 적은 양)
- Visual Genome(sparse, 낮은 퀄리티)
BUT!! 자연어에 대한 데이터는 많은데 비해 기존의 데이터셋들이 따라가지 못하여 논문의 저자들은 4억개의 새로운 데이터셋 ( 이미지 - 텍스트 pair) 이하 WIT(Web Image Text)를 만들었다고 함.
❓❓ 그렇다면, 이 대용량 데이터셋을 어떻게 학습해야 할까..?
>> 바로 Contrastive Learning 방법을 이용하여 학습하면 된다.
Contrastive는 ‘대조하는’ 이라는 뜻을 가진 단어이다.
따라서 Contrastive Learning은 매칭되는 데이터 Feature들끼리는 가까워지도록, 나머지 Feature들끼리는 멀어지도록 학습하는 방법을 의미한다. 즉, 해당 학습 방법은 데이터를 대조해가며 나랑 매칭되는 데이터는 가까워지도록, 다른 데이터는 멀어지도록 모델을 학습하는 방법이다.
이러한 Contrastive Learning 학습 방법은 Self Supervised Learning에서 그 진가를 발휘.
왜? Label 정보가 없어도 어떠한 기준으로 나와 매칭되는지만 설정해주면 학습을 할 수 있기 때문!

위 그림은 CLIP의 Contrastive Learning 방법을 설명한 그림이다.
데이터셋은 이미지와 이 이미지에 매칭되는 자연어로 구성되어 있으며, 이미지는 Image Encoder로, 자연어는 Text Encoder로 Feature를 추출해준다.
이렇게 추출한 Image Feature는 초록색 사각형 (IN)으로, Text Feature는 보라색 사각형 (TN)으로 표현(이때 N은 배치 개수를 의미) 그럼 총 N개의 Image Feature가 있고, 마찬가지로 N개의 Text Feature가 추출되어 있는 상황인데, 이들 각각을 매칭해보면 총 NxN개의 조합이 나오게 된다.
Contrastive Learning은 나와 매칭되는 조합은 가까워지도록, 그 외의 조합은 멀어지도록 학습하는 방법이므로, 이때 가까워진다는 의미는 여기서는 두 Feature의 Cosine Similarity가 커지는 방향을 의미한다. (두개의 Feature가 공간상에서 가까운 각도에 위치할수록 Cosine Similarity는 큰 값을 갖기 때문) 반대로 나머지 쌍과는 멀어지도록 모델을 학습해준다.
(여기서 모델은 Image Encoder와 Text Encoder를 의미)
:
:
우선 하나의 batch는 N개의 이미지-텍스트 쌍으로 구성되어진다. 따라서 N개의 쌍을 모든 i,j에 대해 비교하게 된다면 N개의 positve pair과 N^2 - N개의 negative pair를 얻을 수 있게 된다. (N x N 이 전체 pair이며 그중 positive pair가 N개 이기 때문에 negative pair는 N^2 에서 positive pair를 제외한 N^2 - N 이 됨)
그리고 다음과 같은 4가지 조건을 사용:
- 이미지와 텍스트를 하나의 공통된 Space를 가지게 한다.
- Positive pair에서는 Cosine 유사도를 최대화한다.
- Negative pair에서는 Cosine 유사도를 최소화한다.
- Cross-Entropy Loss를 사용한다.
우선, 텍스트는 텍스트 인코더를 통해 N개의 임베딩이 만들어진다: (T_1 ... T_N)
이미지 또한 이미지 인코더를 통해 N개의 임베딩이 만들어진다:( I_1 ... I_N)
그렇게 되면 총 N x N = N^2개를 예측하게 학습이 진행.
Positive Pair의 유사도는 최대로, Negative Pair는 최소를 목표로 하게 되는데, 이때 위의 그림에서 Positive pair는 파란색 색상이 됨.
왜냐하면, I_1 는 T_1 과 대응되어야 정답 label이기 때문! 대각선으로 Positive pair들이 만들어지고, 나머지 흰색 부분들은 모두 Negative pair들을 의미. 이러한 방법으로 이미지와 텍스트 인코더를 같이 학습함으로써 Multi-Modal 임베딩 공간을 학습하게 된다.
코드를 살펴보자면..

위에서 구한 Positive / Negative score를 기반으로 Cross-Entropy를 계산함을 알 수 있다.
마지막으로, CLIP은 텍스트/이미지 인코더의 representation에서 Multi-modal embedding space로의 Linear Projection만을 사용. 또한, Data Augmentation은 resize만 사용했다고 함.
결국 CLIP 방법론의 핵심은 Image Encoder와 Text Encoder를 Contrastive Learning 방법으로 학습한다는 것!
❓❓ 그렇다면 이 두 인코더는 어떻게 구성했을까…?
Image Encoder / Text Encoder
<Image Encoder>
CLIP의 저자들은 이미지 인코더로 두 개의 구조를 고려 :
- ResNet-50 → ResNet-D
- Vision Transformer(ViT)
1) ResNet-50
오리지날 ResNet에 조금 수정된 버전을 사용했는데, **ResNet-D**버전을 사용했으며 rect-2 blur pooling을 사용했다. 또한, global average pooling 레이어를 **attention pooling 메커니즘**으로 대체했다.
2) ViT
최근 소개된 **Vision Transformer**로도 실험을 했는데 하나의 추가적인 **layer normalization을 추가**하는 것 외에 거의 기존의 모델을 수정하지 않고 사용했다.
<Text Encoder>
텍스트 인코더로는 Transformer를 사용했는데 텍스트의 BPE representation을 이용!
계산 효율성 측면때문에 max sequence length는 76로 제한했고 텍스트 시퀀스는 [SOS]와 [EOS] 토큰과 함께 묶였으며 [EOS] 토큰 위치의 highest laeyrs의 activations은 text의 representation으로 다뤄진다. Masked self-attention이 기존에는 사용되었지만 여기서는 사용하지 않았다.
→ 이전 연구들은 ResNet의 Width나 Depth를 조정하여 모델을 Scaling했으나 해당 논문에서는 그러한 방법은 모델의 한 차원에만 잘 동작한다는 사실을 인지하였기 때문에 굳이 그러한 작업은 하지 않았다고 한다. CLIP이 사용한 Text dataset의 크기가 커서 텍스트 인코더의 Capacity에 민감하지 않았기 때문!
Zero-Shot Prediction이 가능!
CLIP의 가장 재미있는점중 하나는 바로 Zero Shot Prediction이 가능하다는 것!
Zero Shot Prediction이란 말 그대로 한번도 학습하지 않은 문제를 맞추는 방법을 의미한다. 이러한 기능은 기존 ImageNet으로 학습한 모델에서는 기대하기 어려웠는데, 그 이유는 Supervised Learning 방식으로는 학습하지 않은 클래스를 예측하는게 태생적으로 불가능하기 때문!
그런데 재밌는건 CLIP은 Zero Shot Prediction이 가능하다.
❓❓ 어떻게 가능할까…?
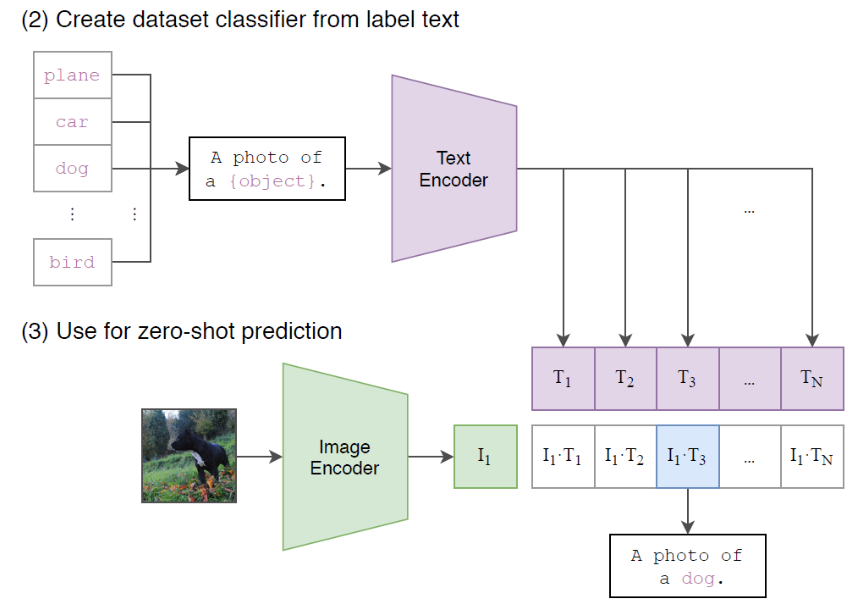
- Zero Shot Prediction을 하려는 이미지 Feature를 추출 >> 이 Feature는 학습 완료된 CLIP의 Image Encoder를 사용하여 추출해주면 된다.(초록색 사각형에 해당)
- 이제 이 그림이 어떠한 클래스에 해당하는지를 연산하기 위해 Text Feature를 추출해야 함모든 N개의 클래스를 이런식으로 해당 클래스를 표현하는 문장으로 만들어 주면 된다.(CLIP이 이렇게 그림을 설명하는 문장을 학습했으므로)
- 우리가 구분하고자 하는 클래스 종류가 N개라고 가정해보자! 그럼 이제 이 클래스들을 설명하는 문장을 만들어줘야 한다. ‘A photo of a dog’ 와 같이!
- N개의 문장을 각각 학습 완료된 CLIP의 Text Encoder로 Feature를 추출해줌. (N개의 보라색 사각형들에 해당)
- 마지막 단계로 추출한 Image Feature와 Text Feature들간의 Cosine Similarity를 측정.
- 해당 이미지를 가장 잘 설명하는 Text Feature와의 Cosine Similarity 값이 가장 크게 나오게 됨. 왜냐하면 CLIP이 바로 그렇게 학습했기 때문! → 위의 이미지에서는 I_1 과 T_3 가 매칭!
이러한 방법을 통해서 CLIP은 고정되지 않은 개수의 클래스에 대해 예측이 가능하다. 이는 기존의 Label을 사용하여 이미지의 클래스를 구분하는 방식이 아닌, 이미지와 자연어의 정렬 (Align)을 학습한 덕분이다!
'📜 Paper > Multi-Modal' 카테고리의 다른 글
| Self-Supervised MultiModal Versatile Networks (2) | 2024.02.28 |
|---|---|
| IMAGEBIND: One Embedding Space To Bind Them All (0) | 2024.02.12 |