
이번 글에서는
"카운트 기반의 문서 표현"에 대해
복습도 할겸 정리하고자 한다
카운트 기반의 문서표현이란❓
문서의 의미를 반영해 벡터를 만드는 건데
쉽게 말하자면 문서마다의 단어의 빈도수를 세고,
이를 통해 각각의 문서 및 텍스트를
이해하는 거라고 볼 수 있다.
그러기 위해서는
텍스트를 우리가 다룰 수 있는
수치 형태로 변환해야 하는데
이때, 수치는 그 텍스트의 "특성"을
이용하면 된다.
텍스트에서 특성이란❓
단어를 의미하는 것이고,
특성의 값은 해당 단어의 빈도수를 의미한다.
우리는 이렇게 정의한 특성과
해당 특성이 가지는 값으로
텍스트를 구분할 수 있다.
이때, 모든 문서의 특서이 같아야
서로 비교할 수 있다는 점을 고려하여
동일한 단어들로 특성을 표현해야 한다.
즉 예를 들어 모든 문서에 대한 단어들로
특성을 구성한다고 가정하면
각 문서에 대해 해당 특성 단어들에 대한 빈도수를
숫자로 표현하면 된다.
만약 특정 문서에 단어가 사용된 적이 없으면
0을 넣어주면 된다.
즉 정리하자면
각 텍스트 및 문서에 대해서
우리가 정의한 특성에 대한 특성 값의 벡터로
변환해야 하는데
카운트 기반 문서 표현에서는
특성이 곧 단어가 되고,
단어의 빈도가 특성의 값이 된다.
이렇게 각 문서에 대해
단어의 빈도수를 계산한 벡터들을
각 문서의 "특성 벡터"라고 부른다
위와 같은 방법을 BOW라고 하며
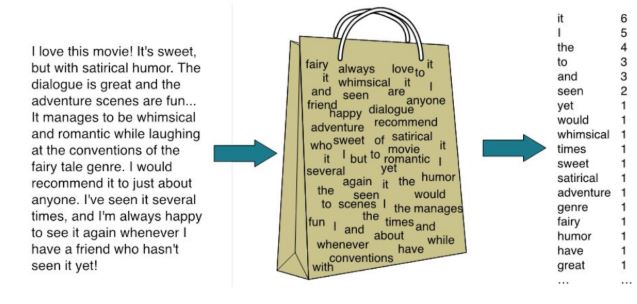
BOW기반 특성 벡터를 추출하는 프로세스는 다음과 같다
1. 텍스트 전처리
> 토큰화, 불용어 제거, 품사 태깅등과 같은 전처리 진행
2. 특성 집합 구성
>특성으로 사용할 단어들의 모임을 구성하는데
이때, 말뭉치 전체 단어로 사용하거나 상위 몇프로의 단어들만
특성 집합으로 사용해도 된다
3. 특성 벡터 추출
> 2번에서 만든 특성집합을 기반으로
각 문서에 대한 빈도수를 계산하여
특성 벡터를 만든다.
> 이때 알아야 할 점은
특성 집합의 단어의 순서와 동일한 순서로
특성 벡터가 반환이 된다
예를 들면 특성 집합이 ['apple','orange'] 이었다면
특정 문서의 카운트벡터는 [apple에 대한 빈도수, orange에 대한 빈도수]가 된다.
이번 포스트에서는
BOW를 활용한 방법인
CountVectorizer와 TF-IDF에 대해 정리할 예정이다
BOW기반 카운트 벡터
우선 BOW기반 카운트 벡터 생성이
어떤 원리로 발생하는지 알아보자.
#1번 과정
> 텍스트 전처리

정규 표현식을 이용하여 토큰화를 진행하고
불용어까지 제거하여
결과를 리스트로 반환
[ [문서1에 대해서 전처리한 결과] , [문서2에 대해서 전처리한 결과] , ...]
#2번과정
>특성 집합 생성

1번 과정으로 반환된 결과가 중첩리스트 형태이기 때문에
중첩 for문을 이용하여 모든 말뭉치에 대한
빈도수 사전을 생성
이때, dictionary.get(word,0)은
사전에 word가 있으면 해당 값을 반환해주고
만약 없으면 0을 반환해준다.
원래는 dictionary.get(word, None)형태가 디폴트인데
여기서는 단어의 빈도수를 계산하는 거이기 때문에
0으로 설정해준 다음
단어가 발견될 때마다 해당 빈도수에 +1을 해줘야 한다.
그리고 sorted()에 정렬하고 싶은 인수를 넘겨주면 된다.
key 옵션에 함수를 지정하면
각 원소에 이 함수를 호출한 결과를 기준으로 대소비교
sorted함수는 인수가 어떤 형태이든
결과로 리스트 형태를 반환한다.
특성집합으로 상위 1000개의 단어을 사용하고 싶을 때는
sorted()를 통해 내림차순 정렬해준 다음
1000개만 추출해주면 된다.

#3번 과정
> 특성 벡터(카운트 벡터) 생성

1번 과정을 통해 각 문서에 대해 전처리를 해준 다음
2번 과정에서 특성집합을 만들어 줬으면
그리고 각 문서에 대해 특성 벡터를 생성해주면 된다.
위 함수를 통해 설명하자면
document에는 특정 문서에 대해서 전처리한 결과를,
word_feature에는 특성집합을 넘겨주면 된다.

모든 문서에 대해서
각각의 특성벡터를 생성하고 싶을 때는
우선 전체 문서에 대해서 전처리한 결과(위에서는 tokens)를
(tokens형태 : [ [문서1 전처리(토큰화,불용어제거)] , [문서2 전처리(토큰화,불용어제거)] ] )
for문을 통해 하나씩 불러오고
그 불러온 애를 함수에 넘겨주면 된다.
그러면 함수에서는 해당 문서에 대한 빈도수 사전으로 만들고
그 빈도수 사전을 바탕으로 카운트 벡터를 리스트 형태로 반환할 것이다.
CountVectorizer
CountVectorizer는 그냥 모든 문서에 대해
특성에 대한 빈도수를 계산하여
이를 특성 벡터로 만들어 주는 라이브러리이다.
위에서 말했던 것처럼
특성집합은 말뭉치 전체에 대한 단어들로 구성하여도 되고
아니면 상위 몇백개의 단어들과 같은
특정 조건에 해당하는 단어들로 특성집합을 구성해도 된다
<카운트 벡터의 주요 메서드>
1. fit(text)
텍스트를 인수로 넘겨주면
해당 텍스트에 대해서
토큰화를 진행하고나서
특성 집합을 만들어 준다.
>객체를 생성할 때
매개변수를 이용하여 조정할 수 있는데
fit()은 이러한 매개변수 값을 이용하여
그에 맞는 특성 집합을 구성해줌
> 예를 들어 max_features라는 인수에는
아래와 같이 특성집합으로 사용할 단어의 개수를 넘겨주면 되는데
" CountVectorizer(max_features=1000) "
만약 어떠한 숫자도 지정을 안했다면
전체 말뭉치에 대해서
특성집합을 구성
> 만약 특성집합을 우리가 직접 설정하고 싶으면
아래와 같이 vocabulary라는 인수에 리스트 형태로 넘겨주면 된다
" CountVectorizer(vocabulary=[특성집합에 사용할 단어들]) "
이때, vocabulary에 특성집합 단어들을 넘겨줬다면
fit()과정을 건너뛰고
바로 transform()을 이용하여
특성 벡터를 추출할 수 있다

하지만 vocabulary를 통해 특성 집합을
설정하지 않았을 경우
바로 transform()을 한다면 에러가 발생하니 유의하자!
2. transform(text)
fit()을 통해 생성한 특성집합을 기반으로
인수로 넘겨준 텍스트에 대해서
카운트 벡터를 생성
> 이때 인수로는 리스트나 행렬 형태를 넘겨줘야 한다!
3. fit_transform(text)
fit()과 transform()의 역할을 수행하여
카운트 벡터를 최종적으로 반환을 하는데
카운트 벡터의 형태를 보면 아래와 같이 나오게 된다

여기서 (0,0) 6을 보자
첫번째 0은 첫번째 문서를 의미
두번째 0은 특성 집합에서 0번째 인덱스(즉, 첫번째 단어)를 의미
마지막 6은 단어의 빈도수가 6이라는 것이다.
즉, 첫번째 문서에서
특성집합에서 1번째에 해당하는 단어의 빈도수가
6이라는 것이다.
이를 toarray()를 통해 행렬로 바꿀 수도 있다

n번째 행은
n번째 문서에 대한
카운트 벡터를 의미
m번째 칼럼은
특성집합에서 m번째에 해당하는 단어에 대한
각 문서의 빈도수를 의미
만약 첫번째 문서의 카운트 벡터를
추출하고 싶다면
reviews_cv.toarray()[0]과 같이
인덱스를 지정해주면 된다.
4. get_feature_names_out()
객체에서 특성집합으로 사용한 단어들을 반환

TF-IDF
TF-IDF는 CountVectorizer와 마찬가지로
BOW기반의 라이브러리이다.
하지만 카운트벡터와는 다르게
빈도수에 대해서 패널티를 부여한다
즉, 모든 문서에서 많이 나타나는 단어에 대해
패널티를 부여한다는 것이다.
영어로 예를 들자면
a, the와 같은 관사에 대해서 패널티를 부여한다는 것이다.
이러한 성질 때문에 카운트 벡터보다
실생활에서 더 많이 사용된다고 한다.
주요 메서드 및 매개변수는
CountVectorizer와 동일하다(하는 역할까지도)
하지만 인수로 뭐를 넘겨주느냐에 따라
객체를 생성할 때
어떤 클래스를
이용할지가 달라진다.
TfidfVectorizer
카운트 벡터와 동일하게 텍스트를 인수로 넘겨줄 때
사용하면 된다.
즉 처음부터 텍스트를 넘겨주어
Tf-idf행렬을 생성
=> TfidfVectorizer().fit_transform(텍스트)

텍스트에 대해서 tf-idf를 적용하고 싶다면
위 사진과 같이 TfidfVectorizer를 이용하면 된다.
TfidfVectorizer객체를 생성할 때
vocabulary를 통해 특성 집합을 넘겨준 것을 확인할 수 있다(카운트 벡터와 동일)
TfidfTransformer
인수로 (카운트)벡터를 바로 넘겨줄 때는
TfidfTransformer를 이용하면 된다.
카운트 벡터를 활용하는 것이기 때문에 시간 절약이 가능
=> TfidfTransformer().fit_transform(카운트 벡터)

위 사진을 보면 똑같은 리뷰에 대해서 적용한 것임에도 불구하고
Tf-idf와 카운트 벡터 적용한 결과가 다르게 나왔다.
tf-idf의 단어의 빈도수를 그 단어가 나타난 문서의 개수로 나눠주고,
countvectorizer는 단어의 개수 그 자체를 보여주기 때문에
위와 같은 차이가 발생하게 되었다.
Cosine Similarity
위에서 만든 카운트벡터를 통해
다양하게 활용할 수 있는데
그 중 하나가 문서 비교할 때이다
즉, 문서 간의 유사도를 측정할 때
카운트 벡터를 활용할 수 있는데,
유사도 계산에 가장 많이 사용되는 척도는
코사인 유사도이다.

즉, 코사인 유사도에서는
벡터의 크기는 중요하지 않고
방향만 보겠다는 뜻이다.
(3,3) 과 (6,6)은 크기가 다르지만
방향이 완전히 일치하므로
이 둘에 대한 유사도는 1이다
(두 벡터간의 사잇각이 0이므로 cos0=1을 이용)
여기서 코사인값은 오로지 0에서 1사이의 값을 가지며
두 문서가 완전히 불일치 할 경우
유사도는 0을 가지며
반대로 완전히 일치할 경우
유사도는 1이 된다.

코사인 유사도는
consine_similarity()를 통해 계산할 수 있는데
이때 인수로는 타겟 대상과 비교할 대상을 순서대로 넘겨주면 된다
이때, 두개의 인수 모두 카운트 벡터의 형태로 넘겨줘야 한다
결과로는 타겟 대상과 비교 대상에 대한 유사도를 array형태로 반환해준다.
이때 크기는 (타깃 문서의 개수 , 비교할 대상의 문서의 개수)
[[ target과 문서1에 대한 유사도, target과 문서2에 대한 유사도, .....]]
>여기서는 타겟문서가 한개이고
이를 전체 문서에 대해서
유사도를 비교하는 것이기 때문에
크기가 (1,2000)이 된다
실습코드
'✍️ STUDY > NLP' 카테고리의 다른 글
| [Text Mining] 감성분석 (1) | 2023.03.22 |
|---|---|
| [Text Mining] 토픽모델링 (0) | 2023.03.08 |
| [Text Mining] 차원 축소 (0) | 2023.02.27 |
| [Text Mining] BOW 기반의 문서 분류 (0) | 2023.02.21 |
| [Text Mining] 텍스트 전처리, 자연어 전처리 (0) | 2023.02.06 |