
Word2Vec

는 context word들에 대한 vectors, 는 center word에 대한 vector가 된다. one-hot encoding 된 vector와의 곱 연산을 통해 word vector를 획득한다.
Optimization은 GD 알고리즘을 사용한다 했지만, 일반적으로 이는 비효율적이다. 왜냐하면 매 update 마다 모든 word의 gradient를 계산하는 것은 시간이 매우 오래걸리기 때문이다. 그러므로 gradient descent 대신 stochastic gradient descent를 사용한다.
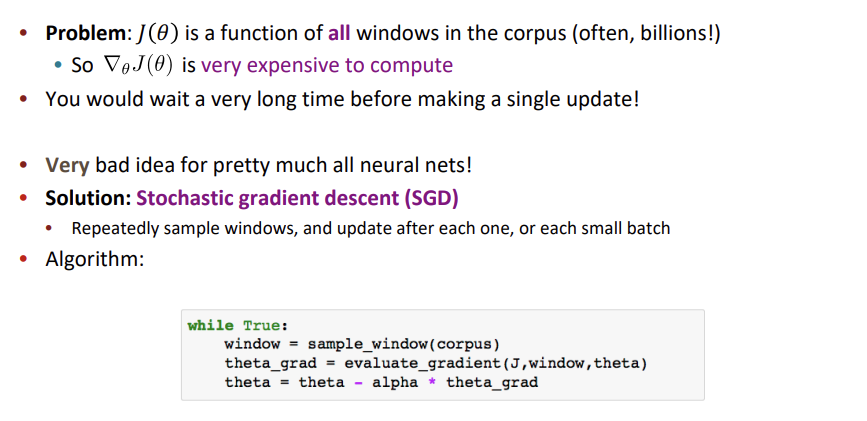
Stochastice gradient descent는 모든 word에 대한 gradient를 계산하여 update 하는 것이 아닌 하나의 word 또는 mini-batch size의 words에 대한 gradient를 계산하여 update를 진행한다.
이때 gradient vector가 매우 sparse 해지는 문제가 발생한다.
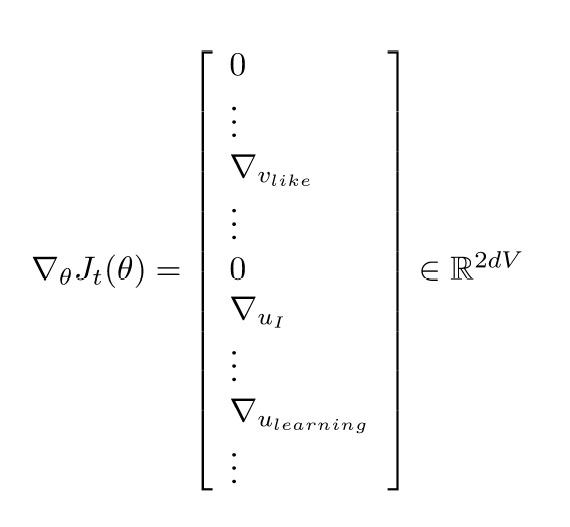
이를 해결하기 위해 update 시 와 의 일부 row 만 update 하는 방식을 사용할 수 있다.
Word2vec algorithm family
Word2vec은 크게 두 개의 alogrithm으로 나뉜다.
1) Skip-grams(SG)
center word가 주어졌을 때 context words를 예측하는 방식.
2) Continous Bag of Words(CBOW)
context words가 주어졌을 때 center word를 예측하는 방식.
Negative Sampling
SG(skip-gram) 모델을 생각하면 probability는 다음과 같다.

이 때 모든 단어에 대한 연산이 분모에 들어가기 때문에 연산에 부담이 된다.
따라서 우리는 이를 해결하기 위해 negative sampling을 사용한다.
negative sampling이란 말그대로 parameter을 update시킬 negative sample을 뽑는것. 즉, 단어 전체를 업데이트 하는것이 아니라, 중심단어와 negative sample 몇개에 해당하는 parameter을 업데이트하는것이다.
무슨말이냐 하면, 우선, 단어 집합을 2가지로 구분할 수 있음. 타겟 단어 주변에 등장한 단어로 구성된 Positive sample, 그리고 타겟 단어 주변에 등장하지 않은 단어로 구성된 Negative sample.
Negative Sampling 기법은 타겟 단어와 주변 단어인 Positive sample은 모두 업데이트하고, 타겟 단어와 거리가 먼 Negative sample은 일부만 추출해서(sampling) 업데이트
negative sampling의 main idea :
- 하나의 ture center, context pair와 몇몇 noise pair만을 이용하여 학습을 진행
- softmax를 사용하지 않고, 대신 logistic function을 이용한다.
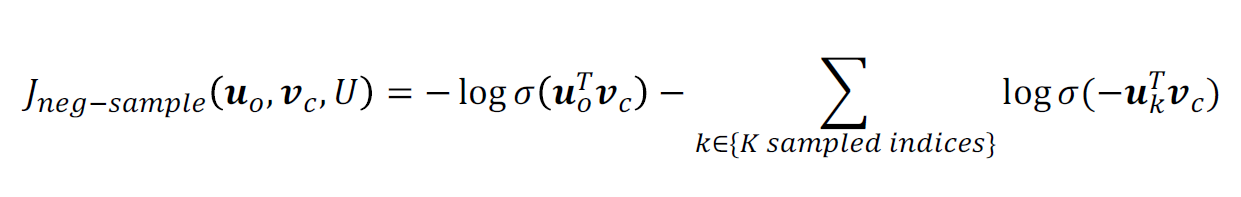
위 식에서 가 negative sampling된 pair의 수를 의미한다. ture pair에 대해서는 maximize 하도록 하고 negative pair에 대해서는 minimize 되도록 한다.
Negative Sampling은 전체 문장에서 자주 사용되는 단어에 높은 가중치를 부여하고, 우선적으로 해당 단어를 선별합니다. 특정 단어가 선별될 확률 수식은 확률로 sampling 한다. 이는 덜 등장하는 word를 더 자주 sampling 하도록 만든다. (는 unigram distribution)
Co-occurence matrix
Word 주변에 동시에 등장하는 words를 count한 matrix.
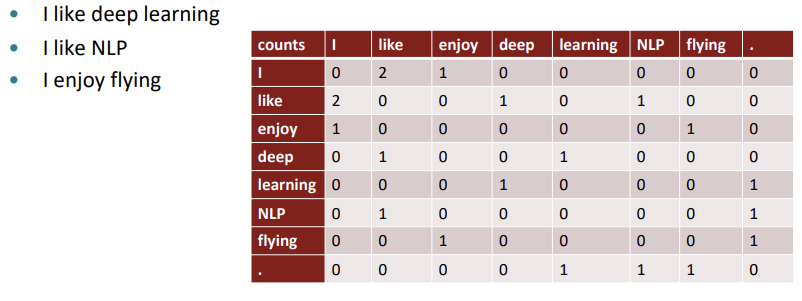
matrix의 row 혹은 column을 word vector로 하는 것을 Co-occurrence vector라고 한다. 이는 매우 sparse하고 high dimension을 지닌다는 단점을 가진다.
따라서 SVD를 이용한 dimension reduction을 수행한다. 이를 통해 dimension을 줄이고 sparse한 vector를 dense하게 만든다.
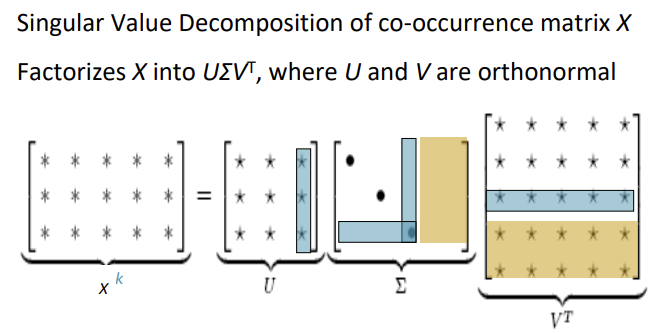
일반적으로 co-occurence matrix에 바로 SVD를 적용하기 보다는 scaling을 적용한 후에 적용한다. the, he, has 같은 단어가 너무 많이 등장하기 때문에 또는 min 등을 이용하여 scaling을 진행한다. 또는 ramp window를 사용하거나 pearson correlation을 count 대신 이용하여 negative value를 0으로 설정하는 방법 등을 쓴다.
Glove
GloVe가 등장하기 이전까지 사용되던 임베딩 방식은 대표적으로 LSA와 Word2Vec 방식이 있다.
LSA의 경우 문서 전체의 각 단어의 빈도수를 담은 행렬이라는 전체적인 통계 정보를 입력으로 받아 차원을 축소(Truncated SVD)하여 잠재된 의미를 끌어내는 방법론이다. 즉, 각 단어의 유사성이나 관계성보다는 문서 전체에 단어가 등장하는 빈도를 통해 단어들을 임베딩하고자 함.

반면,Word2Vec은 window를 사용해 문서 전체가 아니라 중심단어를 둘러싼 주변단어의 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하는 예측 기반의 방법론이다.

이 둘은 각각 장단점이 있는데 LSA는 카운트 기반으로 코퍼스의 전체적인 통계 정보를 고려하기는 하지만 단어 의미의 유추 작업(Analogy task)에는 성능이 떨어짐. 즉, 임베딩된 단어의 선형대수적 연산 능력이 매우 떨어져 단어간의 관계성 부분을 고려하지 못한다.
Word2Vec는 예측 기반으로 단어 간 유추 작업에는 LSA보다 뛰어나지만, 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못한다.
GloVe는 이러한 점을 지적하며 각 임베딩의 방식을 부분적으로 차용하며 등장한 방식이다.
Co-occurence 확률에 대한 ratio는 의미를 담고 있다고 볼수 있다.
Co-occurence 확률은 쉽게 말하면 두 단어가 등장할 조건부 확률이다. 즉, 특정 단어 i의 전체 등장 횟수를 카운트하고, 특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트하여 계산한 조건부 확률 이다. 이때, i는 중심단어 k는 주변단어로 볼 수 있다.
동시 등장 행렬로 파악하면, 중심 단어 i의 행의 모든 값을 더한 값을 분모로 하고 i행 k열의 값을 분자로 한 값이다.
다음은 GloVe의 제안 논문에서 등장한 동시 등장 확률을 표로 정리한 하나의 예시이다.

표를 보면 유사한 단어일 수록 동시 등장 확률이 크고 그렇지 않을 수록 작다. 위의 표에 따르면 ice라는 단어가 주어졌을 때 solid가 등장할 확률은 steam이 주어졌을 때 solid가 나타날 확률보다 높다. 이는 단어의 연관성으로 보았을 때 자명하다.
이때, 은 1보다 훨씬 큰 값(8.9)을 가진다. 반대로 은 1보다 훨씬 작은 값(0.085)이 나오고 ice, steam과 관련성이 높거나 별로 없는 water와 fashion은 모두 1 안팎의 값이 나온다.
Glove는 특정 중심 단어가 주어졌을 때 임베딩된 두 단어벡터의 내적이 두 단어의 동시등장확률 간 비율이 되게끔 임베딩하고자 함. 즉, 중심단어로 어떤 것이 주어지냐에 따라 단어 간의 내적값이 달라지도록 만드는 것이다.
이때 문서를 임베딩하면 중심단어로는 문서 전체의 모든 단어가 설정되므로 최종적으로 문서 전체를 반영하면서도 유사도를 반영한 임베딩 방법론을 구성하고자 함.
그렇기 위해서는 임베딩된 단어들 간의 내적값들이 문서 전체 단어의 분포를 바탕으로 알맞게 조절되어야 한다

Glove의 objective function은 다음과 같다.

Glove는 다음의 장점을 지닌다.
- 빠른 학습
- huge corpora에 대한 scalable
- 작은 corpus와 word dimension에 대해서도 좋은 성능을 보임
Evaluate word vectors
Word vector를 평가하는 방식은 크게 두 가지로 나뉜다.
1) intrinsic
specific/intermediate subtask로 word vector를 평가
빠른 평가가 가능하다
real task의 성능과 다소 차이가 있을 수 있다
e.g) cosine similarity로 단어 유사도 평가
2) extrinsic
real task로 word vector를 평가
평가에 오랜 시간이 걸림
e.g) classification
Word senses and word sense ambiguity
하나의 word는 여러 meaning을 가질 수 있다. (e.g. pike) 하나의 word vector가 여러 meaning을 어떻게 담는지 고민 할 필요가 있다.
Linear algebric 방식으로는 다음과 같이 여러 의미를 하나의 vector에 담도록 만들 수 있다.

'✍️ STUDY > NLP' 카테고리의 다른 글
| [cs224n] Lecture 4 - Syntactic Structure and Dependency Parsing (1) | 2023.11.19 |
|---|---|
| [cs224n] Lecture3 - Backprop and Neural Networks (0) | 2023.11.19 |
| [cs224n] Lecture1 - Intro & Word Vectors (1) | 2023.10.06 |
| [Text Mining] 감성분석 (1) | 2023.03.22 |
| [Text Mining] 토픽모델링 (0) | 2023.03.08 |