
감성 분석은 말 그대로 어떤 텍스트에 대한 감성을 분석하는 것이다.
> 긍정 , 중립, 부정 (또는 긍정, 부정으로만 나눌 때도 있음)
이러한 감성을 분류하는 척도를 "극성"이라고 하며
감성의 정도를 의미한다.
보통은 아래의 기준으로 감성을 분류한다.
0 : 중립
양수 : 긍정
음수 : 부정
감성분석 방법론
감성 분석 하는 방법으로는 크게 2가지로 나눌 수 있다.
1. 어휘 기반 : 감성 사전 구축
감성을 표현할 수 있는 명사, 동사, 형용사를 대상으로
모든 단어에 긍정 혹은 부정의 감성을 붙여 감성 사전을 먼저 구축한 후
이를 기반으로 텍스트에 대한 감성 분석 진행
( 이때 감성 사전은 직접 구축할 수도 있고, 누군가가 이미 구축한 사전을 가져와서 사용할 수도 있다 )
텍스트에 대한 감성을 계산하는 방법으로는
크게 2가지가 있다.
1. 단순합
예를 들어 ['마블','영화','재밌다'] 과 같은 텍스트 토큰이 있을 때
마블, 영화의 극성은 0, 재밌다의 극성은 1로 생각할 수 있다.
그리고 이를 모두 합산을 하면 1이 나오므로 이 문장은 긍정으로 판단이 된다.
하지만 단순합산으로 하면 많은 오류들이 발생하게 된다.
예를 들어 '영화가 재밌거나, 배우들의 연기가 뛰어나거나 시나리오가 재밌는 것은 아니다'라는 문장은
단 한번의 부정으로 문장 전체 부정이 되는데
단순합산으로 계산하게 되면 긍정으로 판단이 되는 오류가 발생하게 된다.
위와 같은 오류를 해결하기 위해 나온 방법이 청킹이다.
2. 청킹(chunking)
문장을 형태소 단위로 분석하고
다시 이를 명사구 , 형용사구와 같이 구로 묶는 방식이다.
즉, 밑에서 부터 단계적으로 올라오는 방식이라고 생각하면 된다.
즉, 청킹을 통해 텍스트의 긍/부정을 판단하게 된다면..
'영화가 재밌거나, 배우들의 연기가 뛰어나거나 시나리오가 재밌는 것은 아니다' 이런 문장이 있을 때
~것은 까지는 긍정이 강했는데
'아니다'라는 말 때문에 부정으로 판단이 된다.
즉, 단순 합산을 통해 발생하게 될 오류들을 해결할 수 있다.
2. 기계학습 기반 : 머신러닝 알고리즘 사용
1번 방법과는 다르게 머신러닝 알고리즘을 이용하여
텍스트에 대한 긍/부정을 예측하는 것이다.
머신러닝 모델을 사용하는 것이기 때문에
모델 학습을 위한 데이터 셋이 존재해야 한다.
예를 들어 머신러닝으로 감성을 판단하고 싶다면
학습용으로 리뷰와 그 리뷰에 대한 감성이
라벨로 짝지어진 학습 데이터 셋이 반드시 있어야 한다
즉, 분류 문제라고 보면 편하다.
기계학습 기반은 학습에 사용한 말뭉치의영향을 많이 받는다.
이러한 성질때문에
어떤 분야의 리뷰로 학습한 모형을
다른 분야의 그대로 전이하여 사용하기에는 무리가 있다
(>> 딥러닝 기반 감성분석과의 차이점 )
감성 사전 기반의 감성 분석 알고리즘에 대해 알아보자.
TextBlob을 통한 감성 분석
Textblob은 감성 분석뿐만 아니라 words, sentence, tags와 같은 다양한 함수 제공
자연어 처리할 때, NLTK 대신 사용해도 된다.
TextBlob을 통해 감성 분석을 진행할 때에는
객체를 생성할 때 인수로 대상 텍스트를 넘겨줘야 한다
#textblob으로 단어 토큰화, 문장 토큰화, 품사태깅 해보기
from textblob import TextBlob
tb=TextBlob(reviews[0]) #인수로 대상 텍스트 넘겨줘야 한다
print(tb.words[:10]) #단어 토큰화
print('\\n')
print(tb.sentences[:10]) #문장 토큰화
print('\\n')
print(tb.tags[:10]) #품사 태깅['plot', 'two', 'teen', 'couples', 'go', 'to', 'a', 'church', 'party', 'drink']
[Sentence("plot : two teen couples go to a church party , drink and then drive ."), Sentence("they get into an accident ."), Sentence("one of the guys dies , but his girlfriend continues to see him in her life , and has nightmares ."), Sentence("what's the deal ?"), Sentence("watch the movie and " sorta " find out ."), Sentence(". .
critique : a mind-fuck movie for the teen generation that touches on a very cool idea , but presents it in a very bad package ."), Sentence("which is what makes this review an even harder one to write , since i generally applaud films which attempt to break the mold , mess with your head and such ( lost highway & memento ) , but there are good and bad ways of making all types of films , and these folks just didn't snag this one correctly ."), Sentence("they seem to have taken this pretty neat concept , but executed it terribly ."), Sentence("so what are the problems with the movie ?"), Sentence("well , its main problem is that it's simply too jumbled .")]
[('plot', 'NN'), ('two', 'CD'), ('teen', 'NN'), ('couples', 'NNS'), ('go', 'VBP'), ('to', 'TO'), ('a', 'DT'), ('church', 'NN'), ('party', 'NN'), ('drink', 'NN')]
#TextBlob으로 감성 분석 진행
.sentiment를 이용하면 대상 텍스트에 대한 극성 수치 제공
* polarity : -1 ~ +1 사이의 값
> 1에 가까울수록 긍정
> .polarity를 이용하여 따로 뺄 수 있음
* subjectivity : 0 ~ +1 사이의 값
> 1에 가까울수록 주관적임을 의미
from textblob import TextBlob
result = TextBlob(reviews[0]) #감성분석하고자 하는 textblob객체 생성
print(result.sentiment) #텍스트에 대한 극성 수치 제공결과
Sentiment(polarity=0.06479782948532947, subjectivity=0.5188408350908352)
즉 위 결과를 보면 극성이 0.06으로 매우 약한 긍정이며, 주관성이 0.51로 중간 정도임을 알 수 있다.
텍스트의 긍.부정 예측을 위해서는
극성 수치를 적절한 기준을 기반으로
문자열로 변환해주는 작업을 거쳐야 한다.
(대부분 텍스트의 감성은 pos/neg와 같은 문자열로 나타나져 있기 때문에)
textblob감성분석 결과는 -1에서 1사이의 수치로 반환해주기 때문에
우리는 이를 pos,neg로 바꾸는 작업을 해줘야 함
기본적으로는
극성수치가 양수이면 긍정, 음수이면 부정으로 나눈다.
def sentiment_TextBlob(docs):
results = []
for doc in docs:
testimonial = TextBlob(doc)
if testimonial.sentiment.polarity > 0: #극성값이 양수이면 긍정으로 : pos
results.append('pos')
else: #0보다 작으면 부정으로 : neg
results.append('neg')
return results
from sklearn.metrics import accuracy_score
print('#TextBlob을 이용한 리뷰 감성분석의 정확도:', accuracy_score(categories, sentiment_TextBlob(reviews)))
#TextBlob을 이용한 리뷰 감성분석의 정확도: 0.6
정확도가 0.6으로 썩 좋지는 않다는 것을 확인할 수 있다.
> 감성 사전을 기반으로 하는 감성 분석은 대부분 정확도가 높은 편은 아님
AFINN을 통한 감성분석
영어가 아닌 언어를 사용하고 싶다면 language 매개변수를 사용
대상 텍스트에 이모티콘이 있자면 emoticon=True라고 설정
🔎TextBlob과 공통점
1. TextBlob과 마찬가지로 알아서 토큰화등의 전처리를 진행
→별도의 전처리없이 바로 텍스트를 인수로 넘겨줘도 된다
2. TextBlob과 마찬가지로 극성값을 수치로 반환
→ 이를 별도로 긍/부정으로 변환해주는 작업 필요
🔎 TextBlob과의 차이점
객체 선언할 때 텍스트를 인수로 넘겨주는 것이 아니라
score 메서드를 호출할 때 텍스트를 인수로 넘겨줘야 한다.
from afinn import Afinn
af=Afinn(emoticons=True) #tb=TextBlob(reviews[0])
af.score(reviews[0]) # tb.sentiment.polarity
16.0
위와 같이 Afinn의 극성값 결과 또한 TextBlob과 같이 숫자이기 때문에
이를 긍/부정(즉, 문자열)으로 바꿔주는 작업 필요!
from afinn import Afinn
def sentiment_Afinn(docs):
afn = Afinn(emoticons=True)
results = []
for doc in docs:
if afn.score(doc) > 0:
results.append('pos')
else:
results.append('neg')
return results
print('#Afinn을 이용한 리뷰 감성분석의 정확도:', accuracy_score(categories, sentiment_Afinn(reviews)))
#Afinn을 이용한 리뷰 감성분석의 정확도: 0.664
→ TextBlob보다는 성능이 좋았지만 여전히 낮은 정확도를 보임 (감성사전 기반 감성분석의 한계점)
VADER를 통한 감성분석
Vader를 사용하기 위해서 vader의 감성사전인 vader_lexicon을 다운로드 받아야 한다.
import nltk
nltk.download('vader_lexicon')
💡 Vader
> Vader는 NLTK에서 제공하는 SentimentIntensityAnalyzer로 진행
SentimentIntensityAnalyzer 는 4가지의 극성값 제공
1. pos : 긍정
2. neg : 부정
3. neu : 중립
4. compound : 위 세 값을 적절히 조합하여 -1과 1의 극성값을 제공
>> compound 값을 기준으로 긍/부정(또는 긍정 중립 부정) 판단 가능
(기준은 마음대로, 대부분 0보다 크면 긍정, 작으면 부정으로 설정)
AFINN과 똑같이 객체를 먼저 선언하고
polarity_scores함수를 통해 극성값을 반환할 때
인수로 텍스트를 넘겨주면 된다
from nltk.sentiment.vader import SentimentIntensityAnalyzer
sta=SentimentIntensityAnalyzer()
sta.polarity_scores(reviews[0])
{'neg': 0.093, 'neu': 0.762, 'pos': 0.145, 'compound': 0.9924}
Vader도 마찬가지로 결과값을 긍/부정으로 바꿔주는 작업 필요!
from nltk.sentiment.vader import SentimentIntensityAnalyzer
def sentiment_vader(docs):
analyser = SentimentIntensityAnalyzer()
results = []
for doc in docs:
score = analyser.polarity_scores(doc)
if score['compound'] > 0: #compound값이 0보다 크면 pos로 설정(기준은 마음대로 해도댐)
results.append('pos')
else:
results.append('neg')
return results
print('#Vader을 이용한 리뷰 감성분석의 정확도:', accuracy_score(categories, sentiment_vader(reviews)))
#Vader을 이용한 리뷰 감성분석의 정확도: 0.635
> 여전히 정확도가 낮음 ( 감성 사전 기반 모델의 한계)
감성 사전 기반 감성 분석은
낮은 정확도를 보인다는 문제점이 있다.
이러한 이유로 대부분의 사람들은
감성 사전 기반의 모델 보다는
머신러닝 또는 딥러닝을 활용하여 감성 분석을 진행한다.
지금부터는 머신러닝 기반의 감성분석 모델을 알아보고자 한다.
지도학습이기 때문에 학습을 위한 데이터셋에 라벨이 반드시 있어야 한다
머신러닝을 통한 감성분석 전반적인 플로우는 아래와 같다.
학습을 통한 감성분석
1. 모델에 적용하기 위해서 텍스트 데이터를 카운트 벡터로 변환
이때 train 데이터에 대해서는 fit_transform을 적용하지만 test 데이터에 대해서는 transform만 적용
2. 카운트 벡터로 변환하고 나서 모델에 적용
train set으로 모델을 훈련(학습) 시키고, test 데이터에 대해서 예측 후 정확도 평가
#카운트 벡터로 변환
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB #sklearn이 제공하는 MultinomialNB 를 사용
tfidf = TfidfVectorizer().fit(X_train)
X_train_tfidf = tfidf.transform(X_train) # train set을 변환
print('#Train set dimension:', X_train_tfidf.shape) # 실제로 몇개의 특성이 사용되었는지 확인
#test_data에 대해서는 transform만 적용
X_test_tfidf = tfidf.transform(X_test) # test set을 변환
print('#Test set dimension:', X_test_tfidf.shape)
#모델 학습 및 예측
> 여기서 모델은 MultinomilNB을 사용
NB_clf = MultinomialNB(alpha=0.01) # 분류기 선언
NB_clf.fit(X_train_tfidf, y_train) #train set을 이용하여 분류기(classifier)를 학습
NB_pred=NB_clf.predict(X_test_tfidf)
print('#Train set score: {:.3f}'.format(NB_clf.score(X_train_tfidf, y_train))) #train set에 대한 예측정확도를 확인
print('#Test set score: {:.3f}'.format(accuracy_score(y_test,NB_pred))) #test set에 대한 예측정확도를 확인
#Train set score: 0.998
#Test set score: 0.797
→ 감성사전에 의한 감성분석보다는 성능이 훨씬 뛰어남
📖 감성분석 진행에 있어 모델을 학습하는 방법 2가지 존재
1. 평점으로 모델 학습 및 예측 진행
> 평점을 Target으로 두고 평점에 대한 예측을 진행
> 예측된 평점을 가지고 임의로 설정한 기준을 바탕으로 긍/부정으로 라벨링
>위에서 라벨링된 값을 가지고 모델 성능 평가 ( 이때 train set의 감성도 긍/부정으로 라벨링)
2. 텍스트 데이터의 평점을 긍/부정으로 나눈 후 이것을 라벨로 변환 후 모델 학습 및 예측 진행
> 평점을 임의로 설정한 기준을 바탕으로 긍/부정으로 라벨링
> 위에서 변환된 라벨링 값을 가지고 학습 및 예측을 진행
(그러면 결과값이 1 또는 0이 나오겠지요)
#1번방법
✔️ 평점으로 먼저 학습 및 예측 진행
from sklearn.linear_model import LinearRegression
lr = LinearRegression() #객체를 생성
lr.fit(X_train_tfidf, y_train)
print('#Regression Train set R2 score: {:.3f}'.format(lr.score(X_train_tfidf, y_train)))
print('#Regression Test set R2 score: {:.3f}'.format(lr.score(X_test_tfidf,y_test)))#lr.score의 척도 : R2
#Regression Train set R2 score: 0.605
#Regression Test set R2 score: 0.395
→ 성능 결과가 썩 좋지는 않음
💡 위에서 모델이 예측한 평점을 긍부정으로 라벨 변환 후 다시 성능 평가
# 예측된 평점을 긍부정으로 변환
: ( >5 , <5 : Boolean성질 이용. 즉 5점보다 크게 예측된 평점은 긍정(True), 작게 예측된 평점은 부정(False) 변환)
y_train_senti = (y_train > 5) #5점이 넘으면 True(긍정), 안 넘으면 False(부정)
y_test_senti = (y_test > 5)
y_train_predict = (lr.predict(X_train_tfidf) > 5) #예측한 값에 대해서도 위의 기준과 똑같이 설정
y_test_predict = (lr.predict(X_test_tfidf) > 5)
from sklearn.metrics import precision_score #정밀도
from sklearn.metrics import recall_score #재현율
from sklearn.metrics import f1_score
print('#Accuracy for train set: {:.3f}'.format(accuracy_score(y_train_senti, y_train_predict)))
print('#Precision for train set: {:.3f}'.format(precision_score(y_train_senti, y_train_predict)))
print('#Recall for train set: {:.3f}'.format(recall_score(y_train_senti, y_train_predict)))
print('#F1 for train set: {:.3f}'.format(f1_score(y_train_senti, y_train_predict)))
print('#Accuracy for test set: {:.3f}'.format(accuracy_score(y_test_senti, y_test_predict)))
print('#Precision for test set: {:.3f}'.format(precision_score(y_test_senti, y_test_predict)))
print('#Recall for test set: {:.3f}'.format(recall_score(y_test_senti, y_test_predict)))
print('#F1 for test set: {:.3f}'.format(f1_score(y_test_senti, y_test_predict)))
#Accuracy for train set: 0.888
#Precision for train set: 0.893
#Recall for train set: 0.969
#F1 for train set: 0.929
#Accuracy for test set: 0.848
#Precision for test set: 0.868
#Recall for test set: 0.946
#F1 for test set: 0.905
>> 성능을 보니 위에 결과보다 훨씬 더 좋아짐
#2번 방법
> 먼저 평점을 긍/부정 라벨로 변환하고나서 학습 및 예측 진행
from sklearn.linear_model import LogisticRegression #sklearn이 제공하는 logistic regression을 사용
#count vector에 대해 regression을 해서 NB와 비교
LR_clf = LogisticRegression() #분류기 선언
#y_train_senti : 0과 1로 라벨링 된 값을 가지고 있음
LR_clf.fit(X_train_tfidf, y_train_senti) # train data를 이용하여 분류기를 학습
y_train_predict = LR_clf.predict(X_train_tfidf)
y_test_predict = LR_clf.predict(X_test_tfidf)
print('#Accuracy for train set: {:.3f}'.format(accuracy_score(y_train_senti, y_train_predict)))
print('#Precision for train set: {:.3f}'.format(precision_score(y_train_senti, y_train_predict)))
print('#Recall for train set: {:.3f}'.format(recall_score(y_train_senti, y_train_predict)))
print('#F1 for train set: {:.3f}'.format(f1_score(y_train_senti, y_train_predict)))
print('#Accuracy for test set: {:.3f}'.format(accuracy_score(y_test_senti, y_test_predict)))
print('#Precision for test set: {:.3f}'.format(precision_score(y_test_senti, y_test_predict)))
print('#Recall for test set: {:.3f}'.format(recall_score(y_test_senti, y_test_predict)))
print('#F1 for test set: {:.3f}'.format(f1_score(y_test_senti, y_test_predict)))#Accuracy for train set: 0.878
#Precision for train set: 0.878
#Recall for train set: 0.973
#F1 for train set: 0.923
#Accuracy for test set: 0.855
#Precision for test set: 0.866
#Recall for test set: 0.958
#F1 for test set: 0.910
>> 1번 방법과 별 차이는 없음
>> 두가지 방법을 다 시도하고 더 나은 모형을 선택하는 것이 좋음
대부분 모델의 평가지표로 정확도를 사용한다.
하지만, 아래와 같이 데이터의 분포가 불균형할 때
모델의 성능을 정확도로 판단하는 것은 많은 문제가 있다.
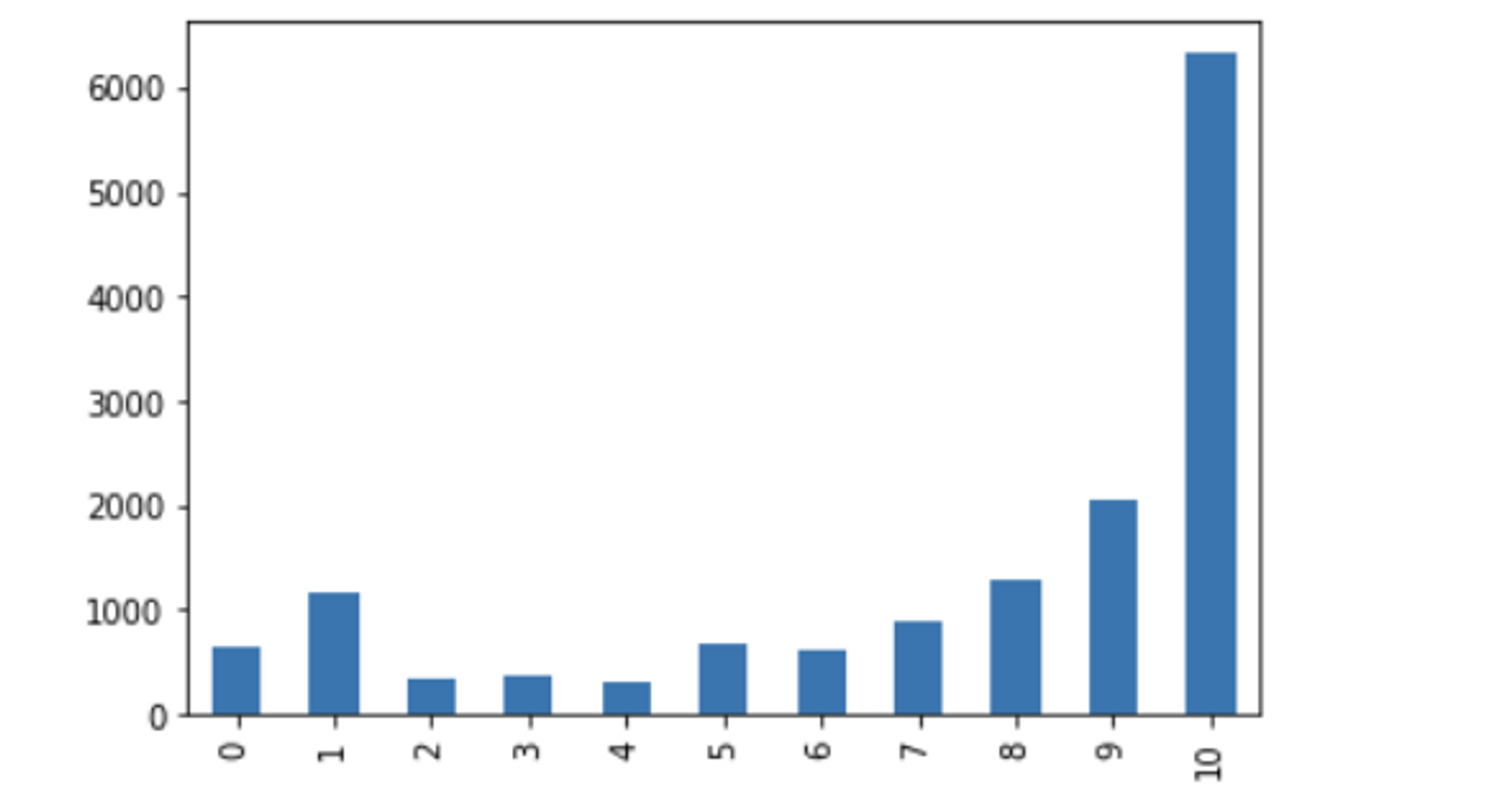
예를 들어 어떤 데이터를 봤는데 긍정이 99프로있고, 부정이 1프로 있다고 가정해보자.
이 데이터를 가지고 모델 학습 및 예측을 진행했을 때
무조건 긍정으로 예측하면 정확도가 99프로가 되버린다
그래서 불균형한 데이터 셋일 경우 정확도로 성능을 평가하기에는 어렵다
불균형한 데이터에서의 성능 측정을 위해 사용되는 지표
재현율 : 실제 긍정인 데이터 중에서 긍정으로 예측한 대상의 비율 ( recall )
정밀도 : 긍정으로 예측한 대상 중에서 실제로 긍정인 데이터의 비율 ( precision )

TP: 실제 긍정인데 긍정으로 예측한 리뷰의 개수
FP: 실제 부정인데 긍정으로 잘못 예측한 리뷰의 개수
TN: 실제 부정인데 부정으로 예측한 리뷰의 개수
FN: 실제 긍정인데 부정으로 잘못 예측한 리뷰의 개수
정확도 : 전체 수에서 올바르게 예측한 리뷰의 수 ( accuracy )
>> (TP + TN) / (TP + TN + FP + FN)
재현율 : 실제 긍정인데 긍정으로 예측한 대상의 비율
>> TP/(TP+FN)
정밀도 : 긍정으로 예측한 대상 중 실제 긍정인 대상의 비율
>> TP /(TP + FP)
'✍️ STUDY > NLP' 카테고리의 다른 글
| [cs224n] Lecture2 - Neural Classifiers (0) | 2023.10.07 |
|---|---|
| [cs224n] Lecture1 - Intro & Word Vectors (1) | 2023.10.06 |
| [Text Mining] 토픽모델링 (0) | 2023.03.08 |
| [Text Mining] 차원 축소 (0) | 2023.02.27 |
| [Text Mining] BOW 기반의 문서 분류 (0) | 2023.02.21 |